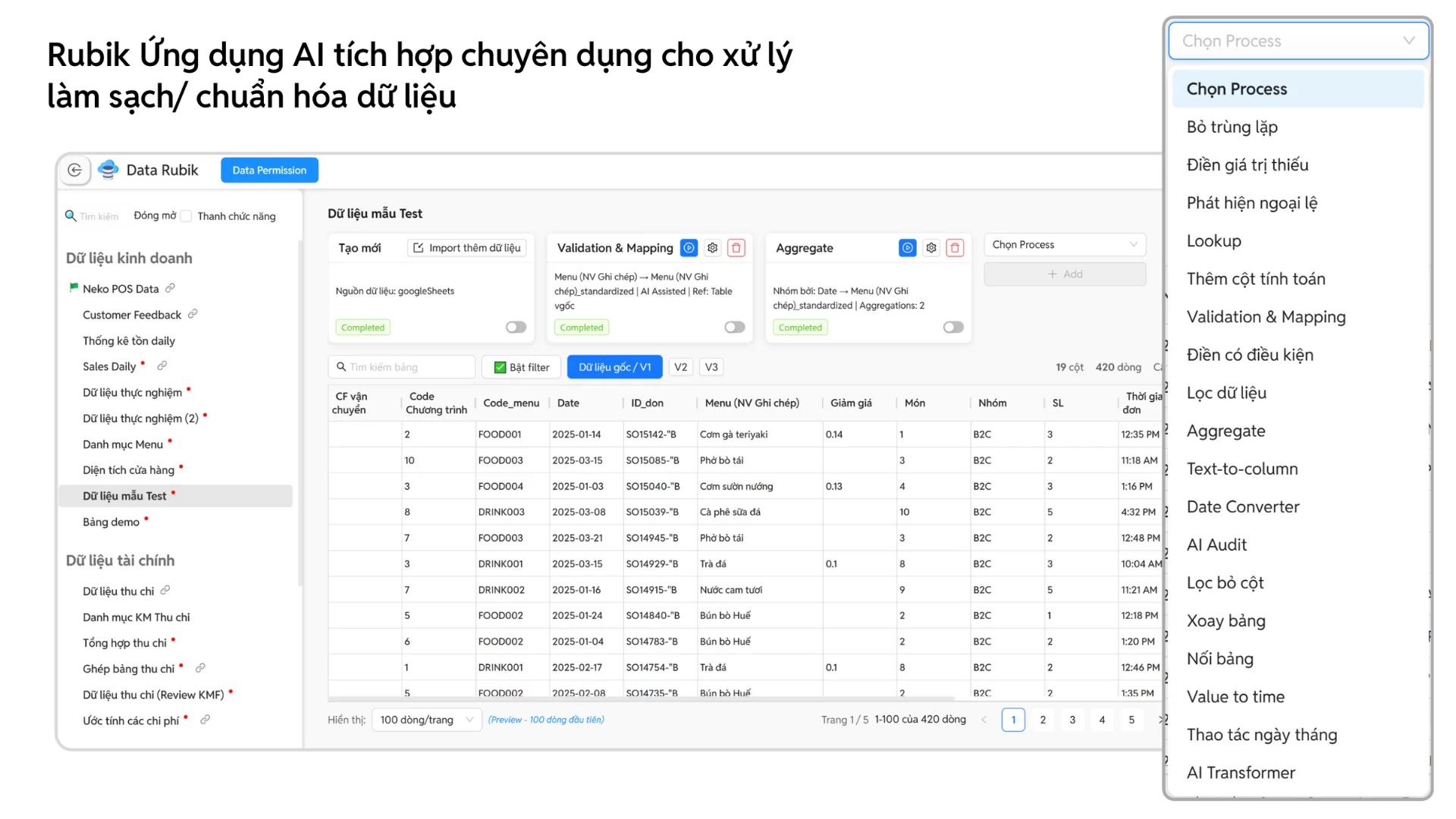
Làm sạch dữ liệu bằng SQL đang trở thành bước gần như bắt buộc trong quy trình phân tích dữ liệu của doanh nghiệp hiện đại. Trong thực tế vận hành, dữ liệu hiếm khi “đẹp” ngay từ đầu: thiếu giá trị, trùng lặp, sai định dạng hoặc không đồng nhất giữa các hệ thống. Nếu không được xử lý đúng cách, những lỗi tưởng nhỏ này có thể khiến dashboard sai KPI, AI dự báo lệch hướng và doanh nghiệp đưa ra quyết định thiếu chính xác.
Chất lượng dữ liệu đầu vào không còn là vấn đề kỹ thuật đơn thuần mà ảnh hưởng trực tiếp đến hiệu quả kinh doanh. Đây cũng là lý do làm sạch dữ liệu bằng SQL được sử dụng rộng rãi trong các hệ thống dữ liệu doanh nghiệp nhờ khả năng xử lý nhanh, trực tiếp trên database và tối ưu hơn nhiều so với thao tác thủ công hoặc xử lý phân tán.
Một trong những vấn đề phổ biến nhất khi phân tích dữ liệu doanh nghiệp là “dữ liệu quá nhiều nhưng insight lại không rõ”. Nguyên nhân thường đến từ việc hệ thống đang lưu cả những dữ liệu không phục vụ mục tiêu phân tích, khiến báo cáo bị nhiễu và làm chậm quá trình xử lý.
>> Đây cũng là bước đầu tiên trong làm sạch dữ liệu bằng SQL mà nhiều doanh nghiệp cần thực hiện trước khi xây dựng dashboard hoặc mô hình phân tích.
Trong thực tế, “dữ liệu không liên quan” sẽ khác nhau tùy vào bài toán kinh doanh. Ví dụ:
Nếu không lọc bỏ từ đầu, các dữ liệu dư thừa sẽ làm sai lệch KPI, tăng chi phí xử lý và khiến kết quả phân tích thiếu chính xác.
Ví dụ, nếu doanh nghiệp chỉ muốn phân tích khách hàng tại Mỹ, có thể dùng câu lệnh SQL sau để lọc dữ liệu:
Câu lệnh này chỉ giữ lại các bản ghi có quốc gia là “US”, giúp tập dữ liệu gọn hơn và đúng với mục tiêu phân tích.
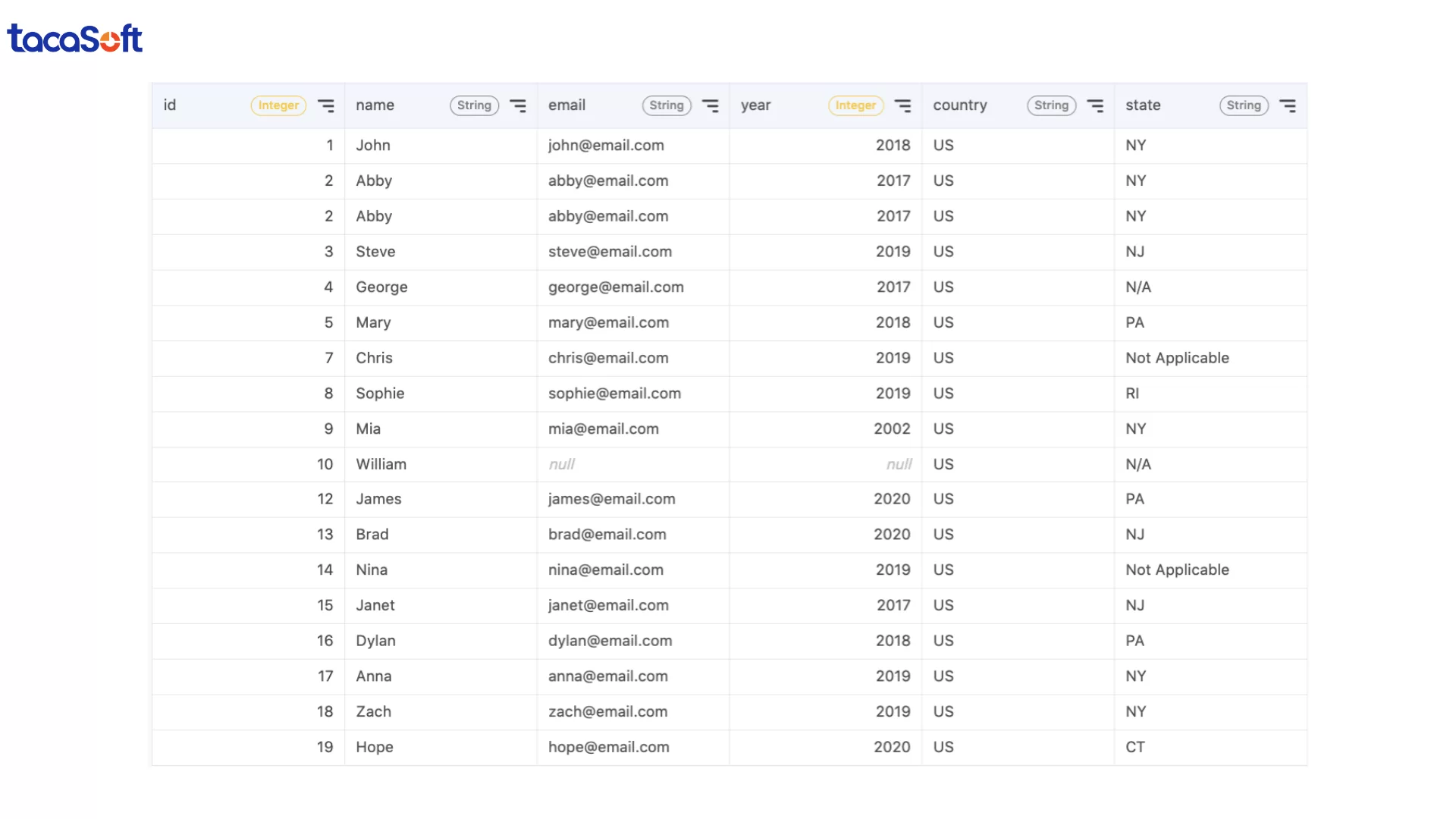
Khi làm sạch dữ liệu bằng SQL, bước loại bỏ dữ liệu không liên quan không chỉ giúp tăng tốc xử lý mà còn đảm bảo doanh nghiệp đang ra quyết định dựa trên đúng nhóm dữ liệu cần thiết, thay vì “phân tích mọi thứ rồi không biết điều gì thực sự quan trọng”.
Dữ liệu trùng lặp là một trong những lỗi phổ biến nhất trong hệ thống dữ liệu doanh nghiệp, đặc biệt khi dữ liệu được tổng hợp từ nhiều nguồn như CRM, form đăng ký, website hoặc nền tảng quảng cáo. Nếu không xử lý sớm, doanh nghiệp rất dễ gặp tình trạng KPI bị “phóng đại”, báo cáo sai lệch và phân tích hành vi khách hàng thiếu chính xác.
Trong thực tế, chỉ một khách hàng bị lưu nhiều lần cũng có thể ảnh hưởng đến:
Ví dụ, nếu bảng customers có nhiều dòng giống nhau cho cùng một khách hàng, doanh nghiệp có thể dùng SELECT DISTINCT để loại bỏ các bản ghi trùng lặp:
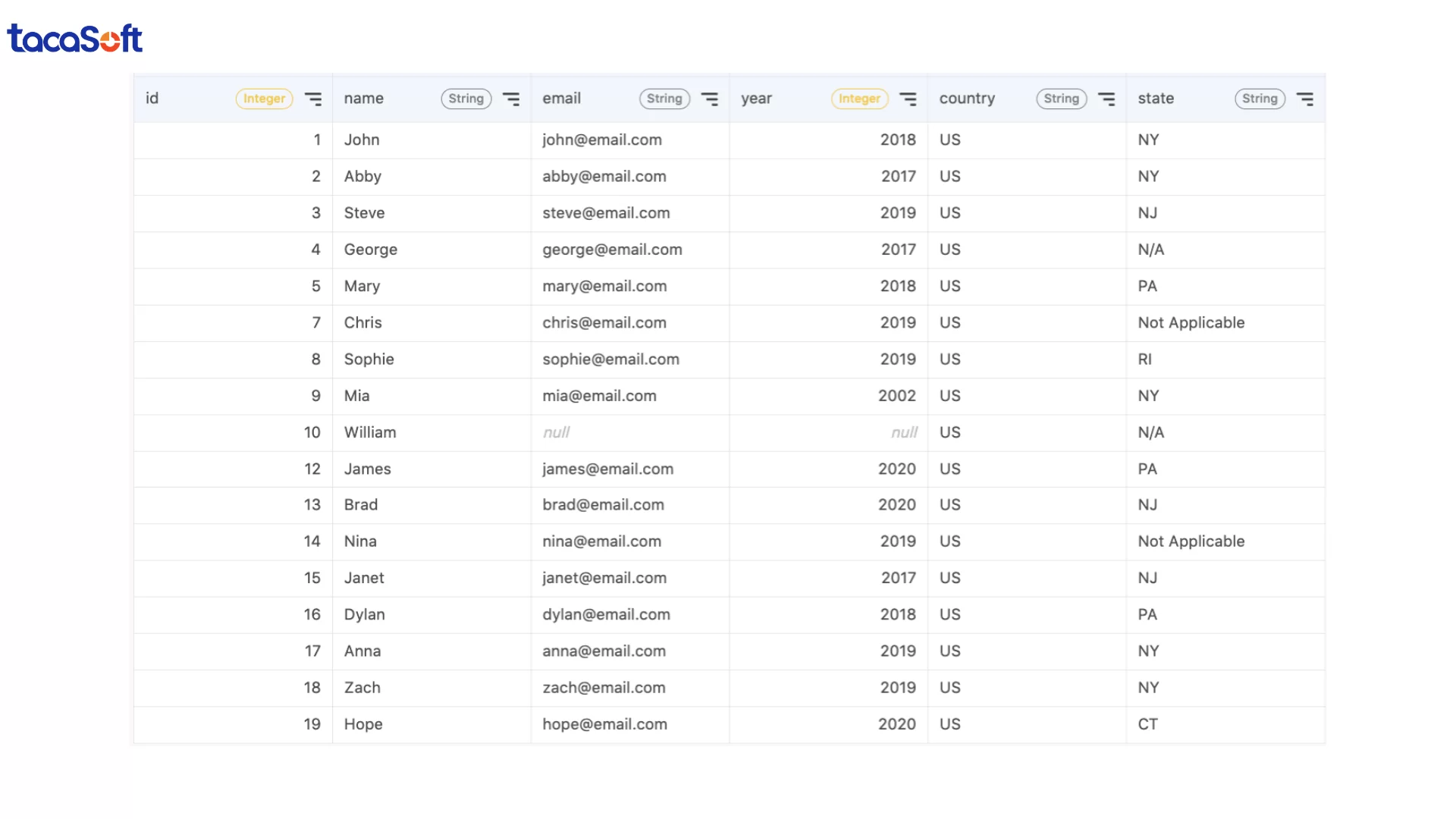
SELECT DISTINCT * thường tiêu tốn nhiều tài nguyên và làm chậm truy vấn.Thay vào đó, trong làm sạch dữ liệu bằng SQL, doanh nghiệp thường sử dụng ROW_NUMBER() để xử lý hiệu quả hơn. Phương pháp này cho phép nhóm dữ liệu theo từng khách hàng và chỉ giữ lại bản ghi mới nhất hoặc quan trọng nhất.
Ví dụ:
PARTITION BY id giúp nhóm các bản ghi theo ID khách hàngORDER BY year DESC ưu tiên dữ liệu mới nhấtROW_NUMBER() = 1 giữ lại duy nhất một bản ghi cho mỗi khách hàngTrong môi trường doanh nghiệp, đây là cách phổ biến để xử lý dữ liệu CRM, lịch sử giao dịch hoặc dữ liệu marketing bị trùng lặp giữa nhiều hệ thống. Khi triển khai đúng, bước này không chỉ giúp dữ liệu “sạch” hơn mà còn giảm đáng kể rủi ro phân tích sai và tối ưu hiệu suất xử lý dữ liệu về sau.
Một trong những lý do khiến nhiều doanh nghiệp “đối số liệu liên tục nhưng không bao giờ khớp” nằm ở các lỗi cấu trúc dữ liệu. Đây là những lỗi rất nhỏ như viết hoa khác nhau, sai chính tả, dư khoảng trắng hoặc cùng một giá trị nhưng mỗi hệ thống lưu theo một kiểu. Tuy nhiên, khi dữ liệu lên dashboard hoặc BI, những sai lệch này có thể khiến KPI bị tách nhóm, báo cáo sai và insight mất độ tin cậy.
Trong thực tế, vấn đề này xuất hiện rất nhiều khi doanh nghiệp:
Ví dụ, chỉ riêng trạng thái khách hàng đã có thể tồn tại dưới nhiều dạng:
N/ANot ApplicableKhông áp dụngNếu không chuẩn hóa dữ liệu, hệ thống sẽ coi đây là ba nhóm dữ liệu khác nhau. Kết quả là dashboard phân tích sai tỷ lệ khách hàng hoặc làm lệch toàn bộ báo cáo vận hành.
Trong làm sạch dữ liệu bằng SQL, doanh nghiệp thường xử lý bằng cách đưa dữ liệu về cùng một chuẩn trước khi phân tích:
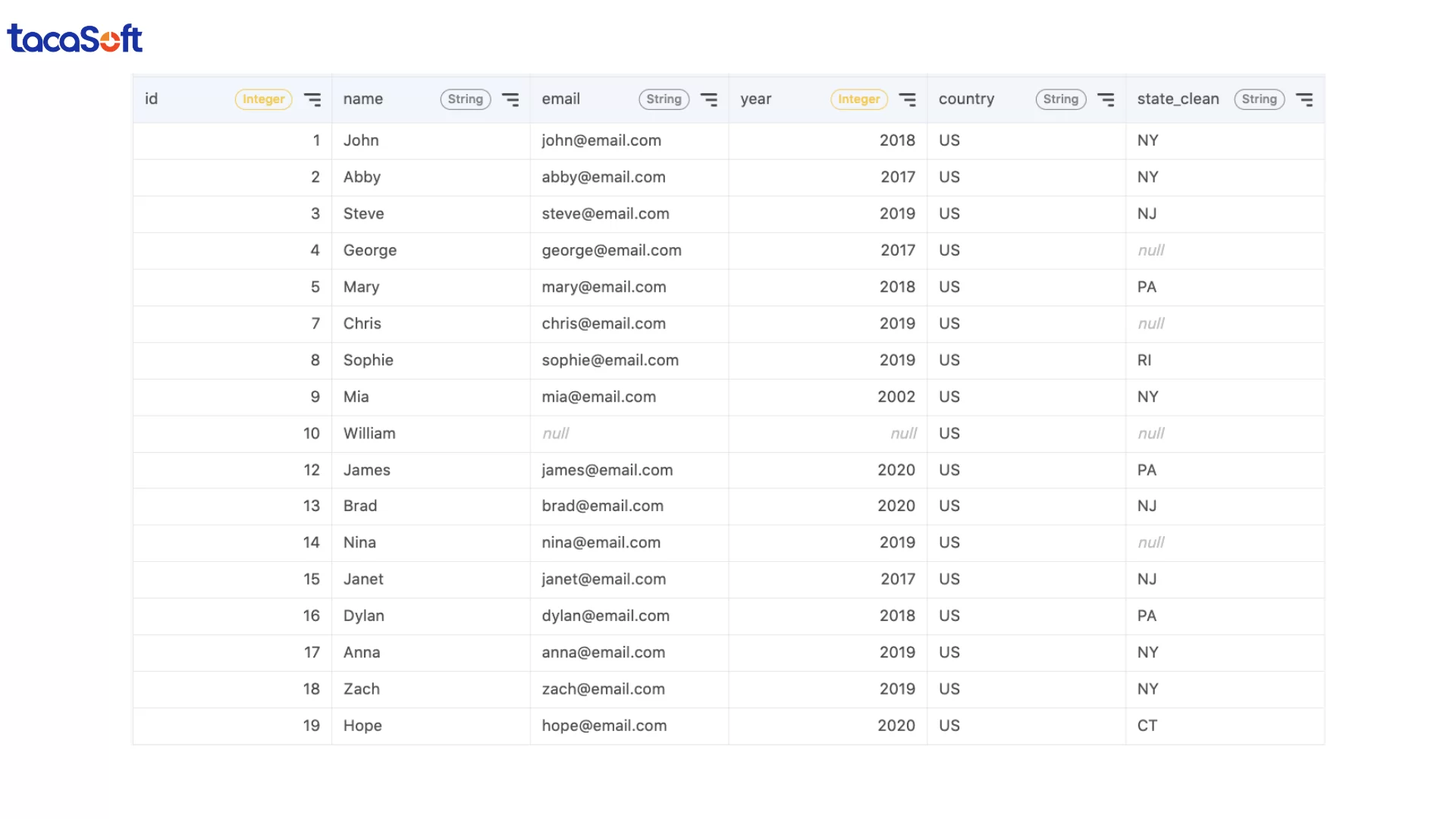
Ngoài việc chuẩn hóa giá trị, SQL còn giúp xử lý nhiều lỗi cấu trúc phổ biến khác:
Điểm quan trọng là lỗi cấu trúc thường không làm hệ thống “báo lỗi”, nhưng lại âm thầm khiến doanh nghiệp đọc sai dữ liệu trong thời gian dài. Vì vậy, trong thực tế vận hành, bước chuẩn hóa dữ liệu không chỉ giúp dashboard sạch hơn, mà còn giúp các phòng ban nhìn cùng một dữ liệu theo cùng một cách – điều rất quan trọng khi ra quyết định.
Một trong những lỗi khiến doanh nghiệp “có dữ liệu nhưng không phân tích được” là dữ liệu đang nằm sai định dạng. Đây là vấn đề rất phổ biến trong thực tế vận hành, đặc biệt khi dữ liệu được đổ về từ nhiều hệ thống khác nhau như CRM, POS, website hoặc file Excel thủ công. Và đây cũng là bước quan trọng trong quy trình làm sạch dữ liệu bằng SQL.
Ví dụ: Doanh thu bị lưu dưới dạng chuỗi ký tự thay vì số, ngày đăng ký hiển thị dưới dạng UNIX timestamp khó đọc, mã bưu chính bị mất số 0 đầu vì hệ thống hiểu nhầm là kiểu số,…
Những lỗi này nghe có vẻ nhỏ, nhưng hậu quả lại rất thực tế:
Trong doanh nghiệp, dữ liệu chỉ thực sự “sử dụng được” khi đúng kiểu dữ liệu ngay từ đầu. Đây là lý do việc chuyển đổi kiểu dữ liệu luôn là bước gần như bắt buộc trước khi đưa dữ liệu vào dashboard, automation hoặc AI.
Ví dụ với bảng customers_zipcode, doanh nghiệp có thể xử lý đồng thời nhiều lỗi bằng SQL:
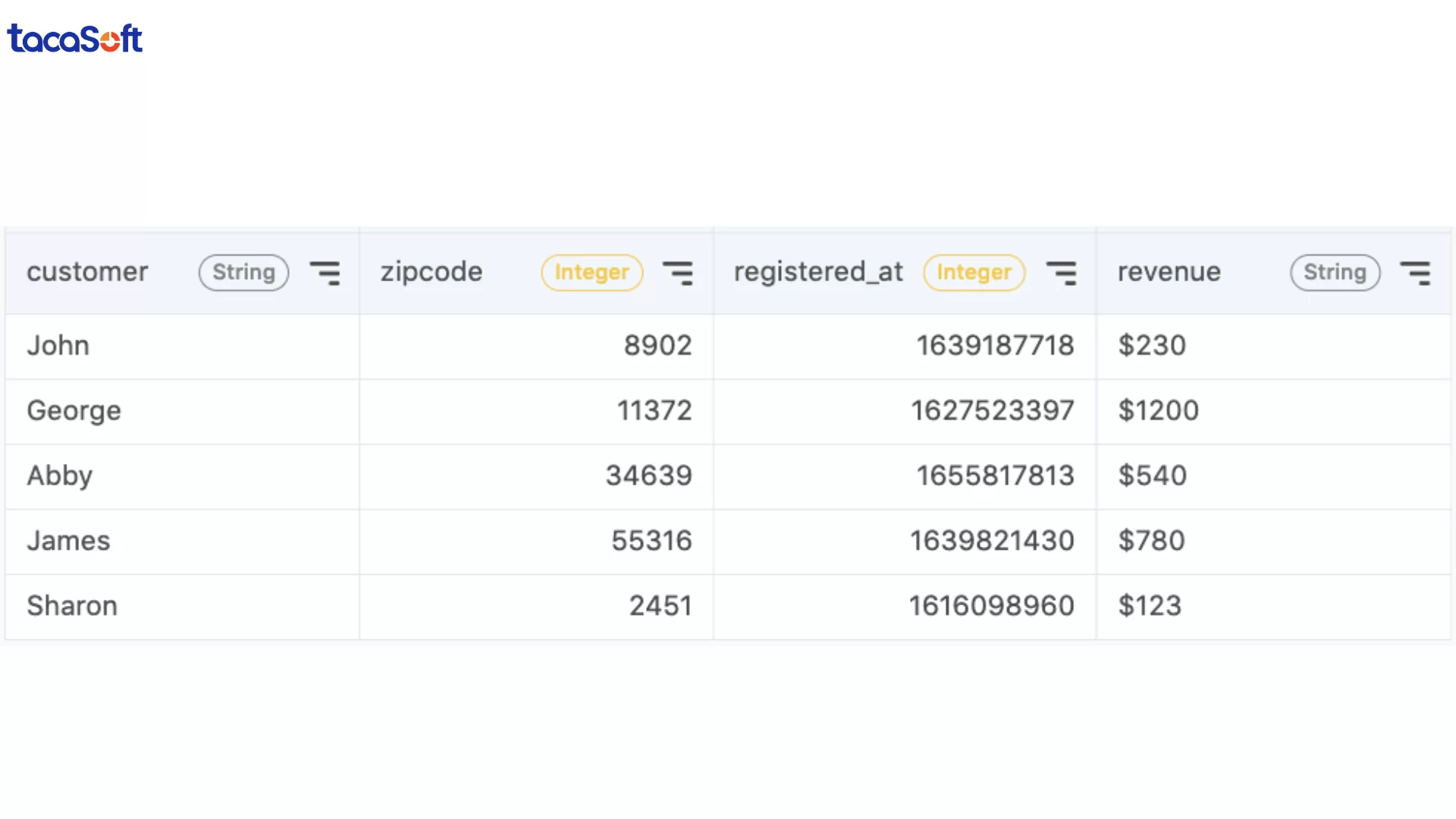
Trong truy vấn này:
CAST() chuyển đổi kiểu dữ liệu để hệ thống có thể xử lý đúngLPAD() thêm số 0 vào mã bưu chính bị thiếuTIMESTAMP_SECONDS() chuyển UNIX timestamp sang định dạng ngày giờ dễ đọcREPLACE() loại bỏ ký tự $ trước khi chuyển doanh thu thành kiểu sốDữ liệu thiếu gần như là vấn đề “không thể tránh khỏi”. Khách hàng bỏ trống thông tin đăng ký, hệ thống tracking lỗi hoặc dữ liệu không đồng bộ giữa nhiều nền tảng – tất cả đều có thể tạo ra các khoảng trống trong dữ liệu. Và nếu không xử lý đúng, đây sẽ là nguyên nhân khiến dashboard sai lệch, AI dự báo thiếu chính xác hoặc báo cáo không phản ánh đúng tình hình kinh doanh.
Đây cũng là bước quan trọng trong quy trình làm sạch dữ liệu bằng SQL, bởi nhiều hệ thống phân tích hoặc BI sẽ không xử lý tốt các giá trị NULL. Trong doanh nghiệp, xử lý dữ liệu thiếu thường xoay quanh hai hướng chính:
Tuy nhiên, cả hai cách đều có đánh đổi.
>> Nếu loại bỏ dữ liệu quá nhiều, doanh nghiệp có thể mất đi những insight quan trọng hoặc khiến mẫu phân tích không còn đủ độ tin cậy. Ngược lại, nếu thay thế dữ liệu thiếu bằng giá trị trung bình hoặc mặc định một cách thiếu kiểm soát, kết quả phân tích có thể bị “làm phẳng”, mất đi biến động thực tế của dữ liệu.
Một trong những tình huống khiến doanh nghiệp dễ đọc sai dữ liệu nhất là các giá trị ngoại lệ (outlier). Đây là những điểm dữ liệu “lệch hẳn” so với phần còn lại, ví dụ:
Trong làm sạch dữ liệu bằng SQL, giá trị ngoại lệ không phải lúc nào cũng là “dữ liệu sai”. Đôi khi đó lại là tín hiệu kinh doanh rất quan trọng. Ví dụ, một đợt doanh thu tăng mạnh có thể đến từ chiến dịch viral thành công, chứ không phải lỗi hệ thống.
Đây cũng là lý do doanh nghiệp cần phân biệt rõ:
Nếu xử lý sai, doanh nghiệp có thể vô tình xóa đi những insight giá trị hoặc ngược lại để dữ liệu lỗi làm lệch toàn bộ báo cáo.
Một phương pháp phổ biến để phát hiện outlier là quy tắc IQR (Interquartile Range) – xác định các giá trị quá thấp hoặc quá cao so với phần lớn dữ liệu còn lại. Trong thực tế, nhiều doanh nghiệp sử dụng phương pháp này để phát hiện bất thường trong:
Điểm quan trọng trong làm sạch dữ liệu bằng SQL là không nên “xóa ngoại lệ theo bản năng”. Trước khi xử lý, cần trả lời được câu hỏi: giá trị này là lỗi hệ thống hay là tín hiệu bất thường đáng chú ý của doanh nghiệp?
Cùng một chỉ số nhưng mỗi hệ thống lại lưu theo một kiểu khác nhau: nơi dùng độ C, nơi dùng độ F; nơi dùng thang điểm 5, nơi dùng thang điểm 100. Khi dữ liệu được đưa lên dashboard hoặc báo cáo tổng hợp, những khác biệt này dễ khiến số liệu bị lệch và gây khó khăn cho việc phân tích.
Trong thực tế, chuẩn hóa dữ liệu giúp doanh nghiệp:
Ví dụ rất phổ biến là dữ liệu đánh giá khách hàng. Nếu một hệ thống lưu theo thang điểm 5 còn hệ thống khác dùng thang điểm 100, doanh nghiệp sẽ khó nhìn ra chất lượng dịch vụ thực sự nếu không quy đổi về cùng một chuẩn.
Tương tự, với các doanh nghiệp đa quốc gia hoặc vận hành nhiều chi nhánh, việc chuẩn hóa tiền tệ, ngày tháng hoặc đơn vị đo lường là gần như bắt buộc để có thể đọc dữ liệu chính xác trên toàn hệ thống.
>> Điểm quan trọng là chuẩn hóa dữ liệu không chỉ giúp “dễ nhìn hơn”, mà còn giúp doanh nghiệp ra quyết định dựa trên cùng một cách hiểu dữ liệu.
Nhiều doanh nghiệp nghĩ rằng làm sạch dữ liệu xong là có thể đưa vào dashboard hoặc AI ngay. Nhưng trên thực tế, doanh nghiệp vẫn cần phải xác thực dữ liệu. Đây là lúc doanh nghiệp kiểm tra xem dữ liệu sau khi xử lý có thực sự đáng tin để phục vụ ra quyết định hay chưa.
Trong quy trình làm sạch dữ liệu bằng SQL, xác thực dữ liệu giúp phát hiện những vấn đề mà hệ thống khó tự nhận ra, ví dụ:
Đây cũng là bước giúp doanh nghiệp tránh một rủi ro rất lớn: dashboard nhìn “rất đẹp” nhưng insight bên trong lại sai. Trước khi đưa dữ liệu vào phân tích hoặc báo cáo, doanh nghiệp thường cần kiểm tra xem dữ liệu đã đủ để phân tích chưa hay còn thiếu nhiều điểm quan trọng, các giá trị có hợp lý với thực tế vận hành không,…
Xem thêm:
Câu trả lời ngắn là: có — đặc biệt với những doanh nghiệp đang lưu trữ dữ liệu trên database, data warehouse. Đúng là hiện nay doanh nghiệp có nhiều lựa chọn để làm sạch dữ liệu như Python, R hoặc các nền tảng BI tích hợp sẵn. Tuy nhiên, trong phần lớn hệ thống dữ liệu hiện đại, SQL vẫn là lớp xử lý gần như bắt buộc vì dữ liệu thường được lưu trực tiếp trong database hoặc warehouse trước khi đi vào dashboard, BI hay AI.
Trong quy trình vận hành thực tế, dữ liệu thường đi qua nhiều bước:
Vấn đề là dữ liệu “bẩn” thường xuất hiện ngay từ các bước đầu tiên này: trùng lặp, sai định dạng, thiếu dữ liệu hoặc không đồng nhất giữa các nguồn. Đây là lý do SQL được dùng rất nhiều để xử lý dữ liệu ngay trong pipeline thay vì chờ tới lúc làm dashboard mới sửa. Điểm mạnh lớn nhất của làm sạch dữ liệu bằng SQL là khả năng xử lý trực tiếp trên hệ thống dữ liệu:
Đặc biệt, với các doanh nghiệp đang dùng BigQuery, Snowflake, Redshift hoặc warehouse cloud, SQL thường hiệu quả hơn nhiều so với xử lý bằng script riêng lẻ vì dữ liệu không cần di chuyển qua nhiều lớp hệ thống.
Tuy nhiên, SQL không phải “giải pháp cho mọi thứ”. Với các bài toán machine learning phức tạp hoặc xử lý dữ liệu phi cấu trúc, doanh nghiệp vẫn thường kết hợp thêm Python hoặc các công cụ Data Engineering khác.