Làm sạch dữ liệu trong Stata là bước nền tảng, quyết định dữ liệu có thể được sử dụng hiệu quả trong phân tích hay không. Dữ liệu tự thân không mang lại giá trị nếu còn tồn tại sai sót, thiếu nhất quán hoặc chưa được chuẩn hóa trước khi đưa vào mô hình.
Thực tế cho thấy, nhiều bộ dữ liệu dù có quy mô lớn vẫn không thể tạo ra kết quả đáng tin cậy do chưa được xử lý đúng cách. Vấn đề không nằm ở lượng dữ liệu, mà ở quy trình làm sạch dữ liệu chưa được thực hiện một cách hệ thống: từ phát hiện giá trị thiếu, xử lý ngoại lệ đến chuẩn hóa định dạng và kiểm tra tính nhất quán.
Khi làm sạch dữ liệu trong Stata đúng cách, doanh nghiệp có thể đảm bảo tính chính xác của kết quả, giảm thiểu sai lệch và nâng cao độ tin cậy của phân tích. Ngược lại, nếu bỏ qua hoặc thực hiện sơ sài bước này, toàn bộ mô hình dù phức tạp đến đâu cũng có nguy cơ phản ánh sai bản chất.
4 phương pháp làm sạch dữ liệu trong Stata cho doanh nghiệp
1. Kiểm tra và xử lý dữ liệu bị thiếu trong Stata
Trong môi trường doanh nghiệp, dữ liệu thiếu không chỉ là vấn đề kỹ thuật mà là rủi ro trực tiếp đến quyết định kinh doanh. Một vài giá trị bị thiếu ở các biến quan trọng (doanh thu, chi phí, tồn kho…) có thể khiến báo cáo sai lệch, kéo theo dự báo và kế hoạch vận hành thiếu chính xác.
Kiểm tra dữ liệu thiếu
Trước khi xử lý, cần xác định rõ dữ liệu đang thiếu ở đâu và mức độ ảnh hưởng:
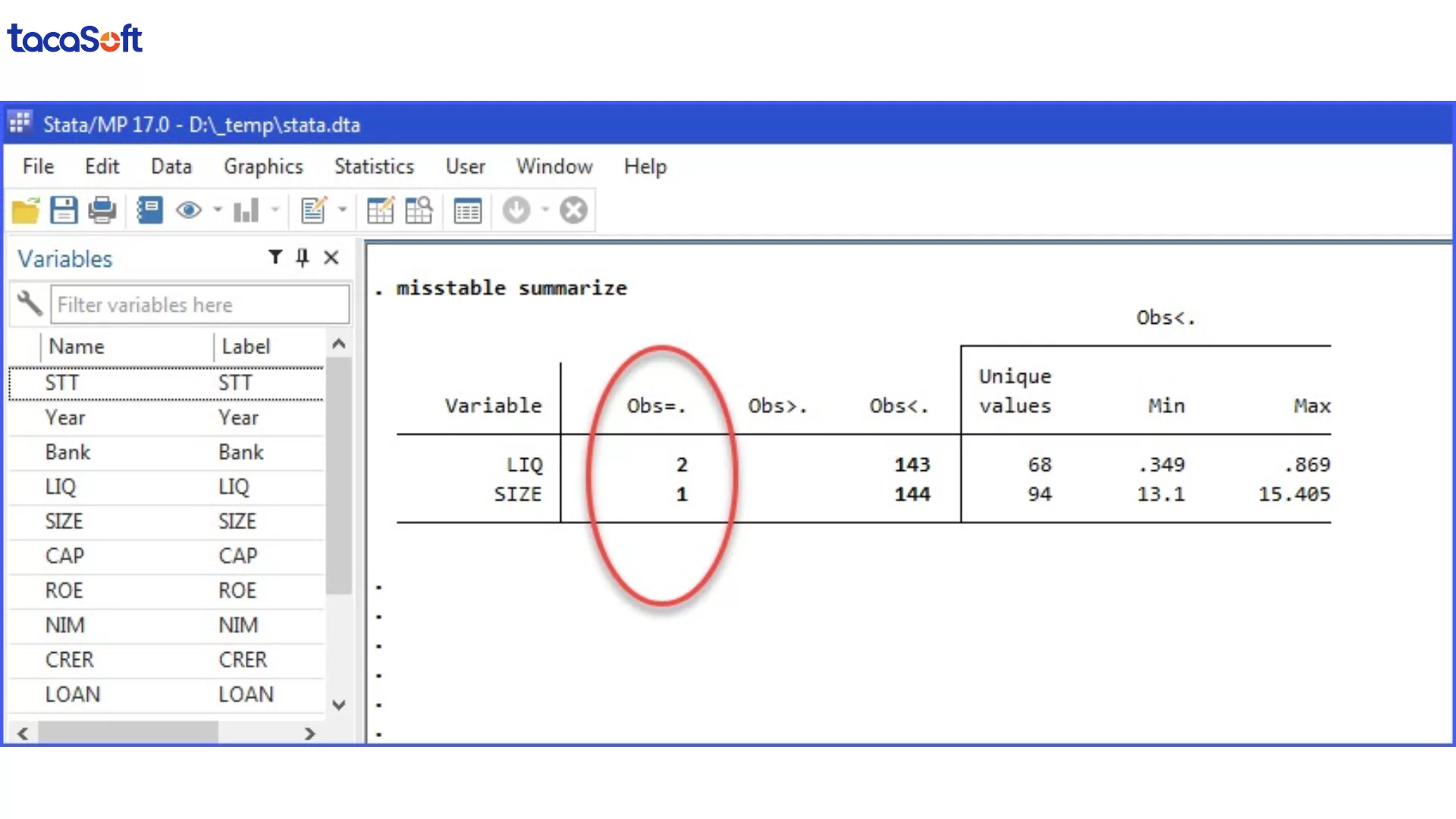
misstable summarize
Lệnh này giúp doanh nghiệp nhanh chóng nhìn ra biến nào đang “có vấn đề”, tỷ lệ thiếu bao nhiêu để ưu tiên xử lý. Trong thực tế, không phải cứ thiếu ít là an toàn — chỉ cần thiếu ở biến “nhạy” (ví dụ dòng tiền hoặc lợi nhuận) là đủ làm sai toàn bộ bức tranh.
Như hình dưới, bài có rất nhiều biến, nhưng chỉ có 2 biến bị thiếu là biến LIQ thiếu 2 và biến SIZE thiếu 1.
Làm sạch dữ liệu trong Stata: Kiểm tra dữ liệu thiếu
Xử lý dữ liệu thiếu
Xóa dữ liệu thiếu (khi cần độ sạch cao)
drop if missing(varname)
Phù hợp khi dữ liệu thiếu chiếm tỷ lệ nhỏ và không ảnh hưởng đến quy mô mẫu. Doanh nghiệp thường dùng trong báo cáo tài chính hoặc dashboard cần độ chính xác cao.
Điền giá trị thay thế (khi cần giữ đủ dữ liệu để phân tích)
replace varname = mean(varname) if missing(varname)
Cách này giúp giữ lại dữ liệu để phục vụ mô hình dự báo hoặc phân tích xu hướng. Tuy nhiên, nếu lạm dụng, có thể làm “mượt hóa” dữ liệu và che mất biến động thực tế.
Góc nhìn thực tiễn: Không có một cách xử lý “đúng tuyệt đối”. Doanh nghiệp cần lựa chọn dựa trên mục tiêu:
Nếu ưu tiên độ chính xác báo cáo → loại bỏ dữ liệu lỗi.
Nếu ưu tiên khả năng phân tích và dự báo → giữ dữ liệu, nhưng thay thế có kiểm soát.
Điểm quan trọng không nằm ở việc xử lý missing values theo kỹ thuật nào, mà là xử lý theo cách giúp dữ liệu thực sự phục vụ được quyết định kinh doanh.
2. Phát hiện và xử lý dữ liệu ngoại lai (outliers)
Trong vận hành doanh nghiệp, không ít báo cáo “đẹp số” nhưng lại sai bản chất chỉ vì vài điểm dữ liệu bất thường. Một đơn hàng bị nhập sai thêm một số 0, một giao dịch hiếm gặp nhưng giá trị quá lớn, hay một lỗi hệ thống ghi nhận sai — tất cả đều có thể kéo lệch trung bình, bóp méo xu hướng và khiến nhà quản lý nhìn sai bức tranh kinh doanh.
Vì vậy, phát hiện outliers không đơn thuần là bước kỹ thuật, mà là bước kiểm soát rủi ro dữ liệu trước khi ra quyết định.
Kiểm tra outliers
Trong Stata, chỉ cần một lệnh đơn giản:
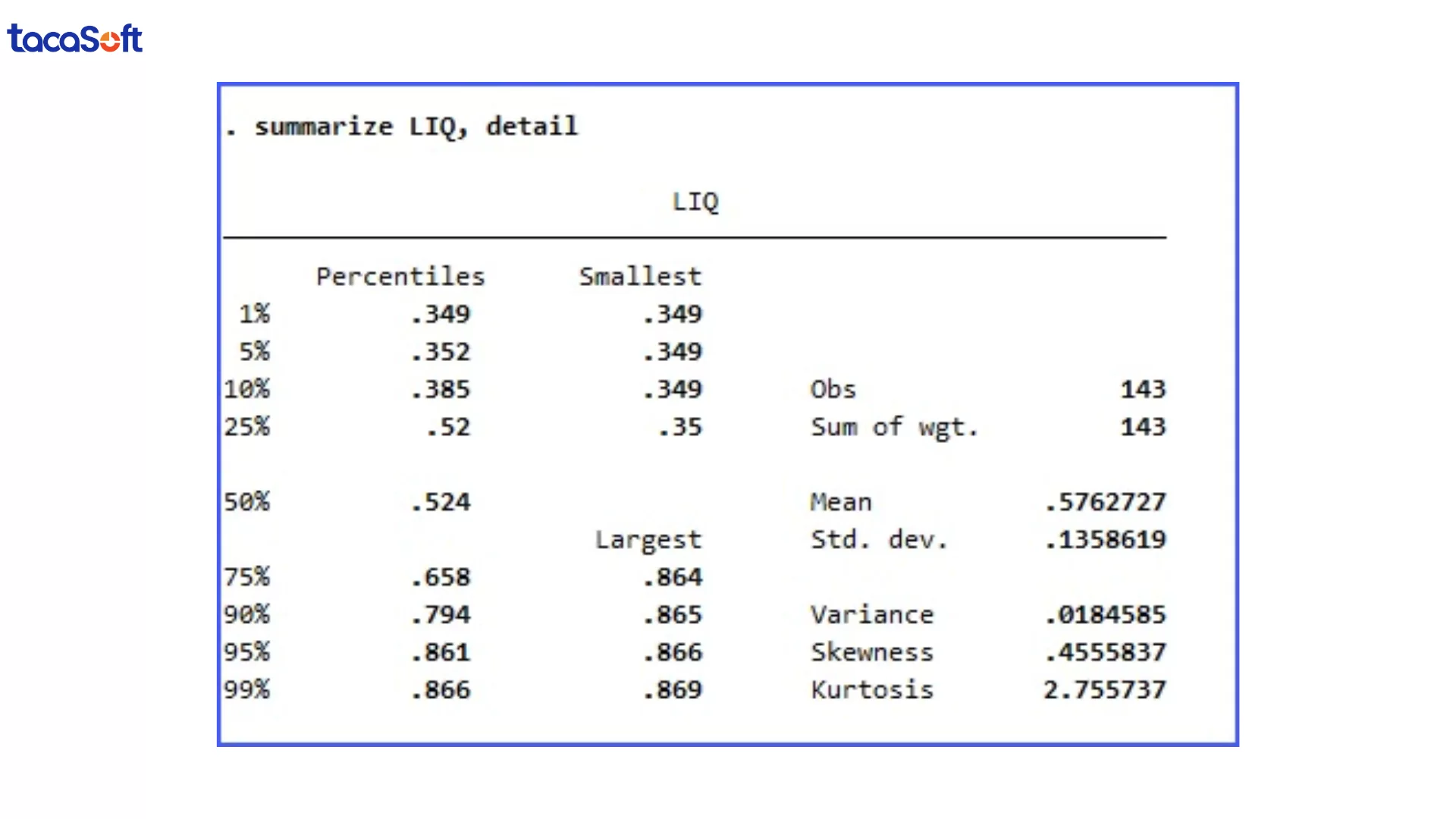
summarize varname, detail
là đã có thể “soi” nhanh toàn bộ phân phối dữ liệu. Khi giá trị lớn nhất hoặc nhỏ nhất nằm quá xa so với phần còn lại, đó là tín hiệu cần được kiểm tra. Trong thực tế, nhiều doanh nghiệp phát hiện sai lệch doanh thu hoặc chi phí không phải qua mô hình phức tạp, mà từ chính bước rà soát cơ bản này.
Làm sạch dữ liệu trong Stata: Kiểm tra outliers
Xử lý outliers
Nếu outlier đến từ lỗi nhập liệu hoặc lỗi hệ thống, việc loại bỏ là cần thiết để tránh làm sai báo cáo:
drop if varname > ngưỡng
Nếu outlier phản ánh thực tế kinh doanh (ví dụ: khách hàng chi tiêu rất cao), việc xóa đi có thể đồng nghĩa với việc mất insight quan trọng. Khi đó, thay vì loại bỏ, doanh nghiệp thường chọn cách “giảm ảnh hưởng” bằng biến đổi dữ liệu:
gen log_var = log(varname)
Một cách tiếp cận thận trọng hơn là đánh dấu để theo dõi riêng:
gen outlier_flag = (varname > ngưỡng)
Điều này giúp tách nhóm dữ liệu đặc biệt để phân tích sâu hơn, thay vì xử lý một cách “cơ học”.
Outliers có thể là lỗi — nhưng cũng có thể là tín hiệu. Một giá trị bất thường có thể là dữ liệu sai, nhưng cũng có thể là khách hàng lớn nhất, thị trường mới hoặc một biến động đáng chú ý.
Do đó, vấn đề không nằm ở việc loại bỏ hay giữ lại, mà ở việc doanh nghiệp hiểu đúng bản chất của dữ liệu trước khi đưa ra quyết định. Trong nhiều trường hợp, chính những “điểm lệch chuẩn” lại là nơi chứa đựng thông tin giá trị nhất.
3. Kiểm tra và chuẩn hóa dữ liệu trong Stata
Trong nhiều doanh nghiệp, dữ liệu không “sai” nhưng lại không dùng được — chỉ vì thiếu chuẩn hóa dữ liệu. Tên khách hàng viết hoa – viết thường lẫn lộn, tên ngân hàng nhập dạng chữ, định dạng không đồng nhất… tất cả khiến mô hình không thể chạy, hoặc tệ hơn là cho ra kết quả thiếu nhất quán.
Chuẩn hóa dữ liệu vì thế không phải là bước làm cho “đẹp dữ liệu”, mà là điều kiện để dữ liệu có thể đi vào phân tích và tạo ra giá trị thực tế.
Một trong những vấn đề phổ biến là dữ liệu định tính (string) không thể sử dụng trực tiếp trong các mô hình. Khi đó, cần chuyển đổi sang dạng số:
encode Bien_String, generate(Bien_DinhLuong)
Việc mã hóa này giúp các biến danh mục (ví dụ: loại khách hàng, khu vực, ngân hàng…) có thể được đưa vào hồi quy, phân tích xu hướng hoặc phân khúc dữ liệu.
Tình huống thực tế: dữ liệu panel trong doanh nghiệp
Khi làm việc với dữ liệu theo thời gian (panel data), việc chuẩn hóa lại càng quan trọng. Ví dụ, nếu tên doanh nghiệp hoặc ngân hàng đang ở dạng chữ (ACB, Vietcombank…), Stata sẽ không thể nhận diện để thiết lập cấu trúc dữ liệu.
Giải pháp là mã hóa trước, sau đó mới khai báo panel:
encode Bank, gen(FIRM_CODE)
xtset FIRM_CODE Year
Nếu bỏ qua bước này, toàn bộ phân tích theo thời gian — từ theo dõi hiệu suất đến dự báo — đều không thể thực hiện.
Dữ liệu không chuẩn hóa giống như dữ liệu “chưa sẵn sàng vận hành”.
Không đưa vào mô hình được
Không so sánh được giữa các nhóm
Không tích hợp được giữa các hệ thống
Ngược lại, khi được chuẩn hóa đúng cách, dữ liệu trở thành tài sản có thể khai thác: chạy mô hình, phân tích hành vi, theo dõi hiệu suất và hỗ trợ ra quyết định. Trong nhiều trường hợp, khác biệt giữa một báo cáo “cho có” và một phân tích tạo ra giá trị nằm chính ở bước chuẩn hóa dữ liệu này.
4. Loại bỏ dữ liệu trùng lặp trong Stata
Trong thực tế doanh nghiệp, dữ liệu trùng lặp là một trong những nguyên nhân “âm thầm” làm sai lệch báo cáo. Một giao dịch bị ghi nhận hai lần có thể khiến doanh thu bị thổi phồng, số lượng khách hàng bị đếm sai, hoặc hiệu suất vận hành bị đánh giá lệch thực tế.
Vấn đề không nằm ở việc dữ liệu nhiều hay ít, mà ở việc dữ liệu có bị lặp mà không được kiểm soát hay không.
Phát hiện dữ liệu trùng
Trước khi xử lý, cần xác định rõ mức độ trùng lặp:
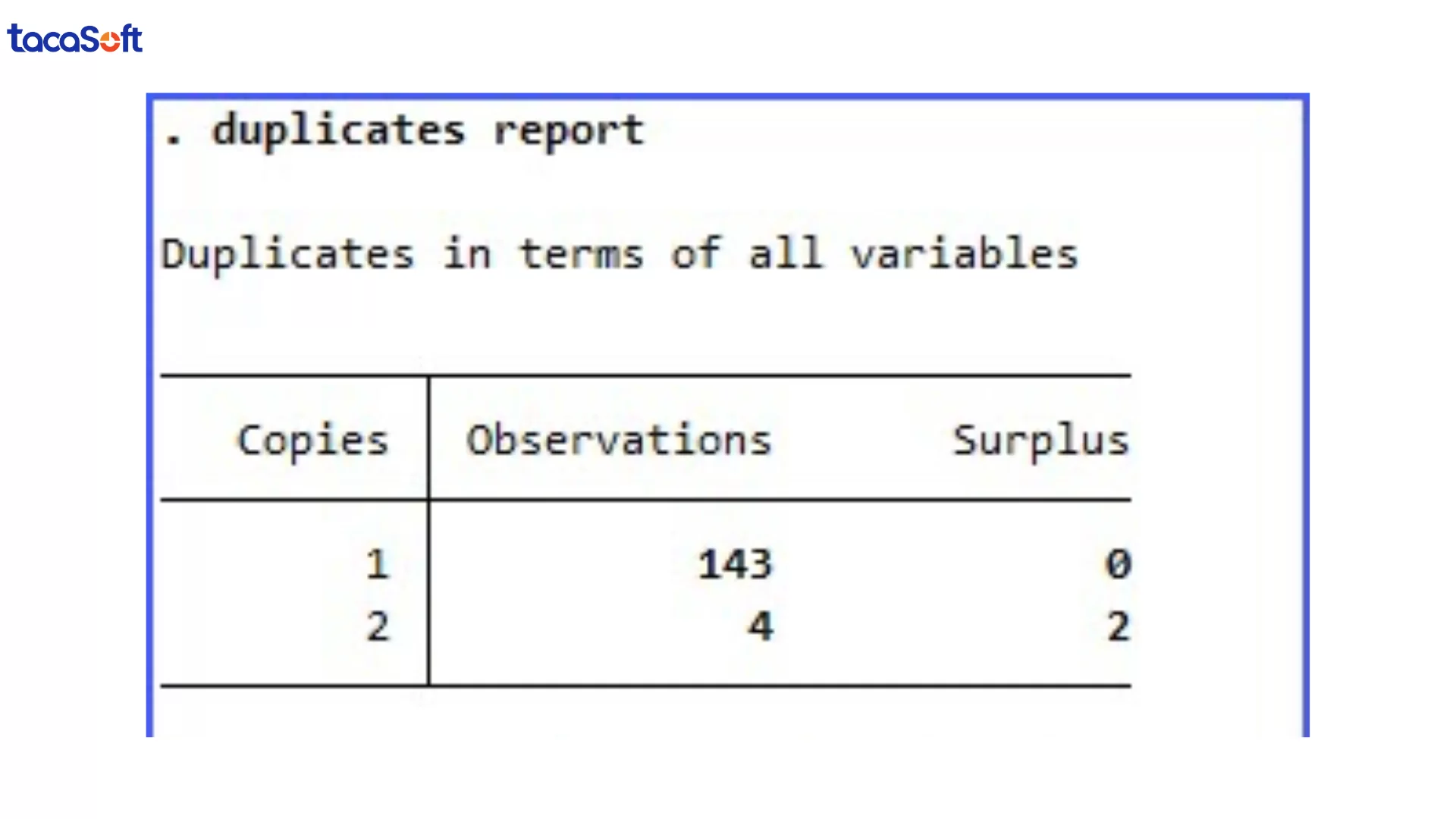
duplicates report
Lệnh này giúp nhanh chóng chỉ ra có bao nhiêu dòng bị trùng và mức độ nghiêm trọng của vấn đề. Trong nhiều hệ thống, đặc biệt là khi dữ liệu được nhập từ nhiều nguồn, trùng lặp xảy ra thường xuyên hơn doanh nghiệp nghĩ.
Làm sạch dữ liệu trong Stata: Phát hiện dữ liệu trùng
Xóa dữ liệu trùng
duplicates drop varname, force
Tuy nhiên, đây là bước cần đặc biệt thận trọng. Nếu chỉ dùng một biến để xác định trùng lặp, Stata có thể xóa hàng loạt dòng có cùng giá trị ở biến đó — dù thực tế đó là các giao dịch khác nhau.
Vì vậy, trong thực tiễn, doanh nghiệp cần:
Xác định đúng tổ hợp biến đại diện cho một bản ghi (ví dụ: mã khách hàng + thời gian + mã giao dịch)
Đưa đầy đủ các biến đó vào lệnh để tránh xóa nhầm dữ liệu hợp lệ
Tuy nhiên, không phải dữ liệu trùng nào cũng nên xóa ngay. Một số trường hợp trùng lặp không phải do lỗi, mà do:
Dữ liệu được ghi nhận nhiều lần từ các hệ thống khác nhau
Thiếu mã định danh duy nhất (unique ID)
Khi đó, thay vì xóa ngay, cần kiểm tra và chuẩn hóa lại dữ liệu trước. Trong nhiều doanh nghiệp, bước này thường đi kèm với việc thiết lập lại quy trình nhập liệu hoặc đồng bộ hệ thống.
Doanh nghiệp có nên làm sạch dữ liệu trong Stata?
Trong kỷ nguyên dữ liệu, câu hỏi không còn là “có nên làm sạch dữ liệu hay không”, mà là “làm sạch dữ liệu tốt đến mức nào”. Với các doanh nghiệp làm sạch dữ liệu trong Stata, đây không chỉ là bước tiền xử lý kỹ thuật, mà là nền tảng quyết định độ tin cậy của toàn bộ chiến lược phân tích.
Về mặt vận hành, làm sạch dữ liệu trong Stata cung cấp hệ thống lệnh mạnh mẽ như duplicates report, duplicates drop, assert, replace, recode, giúp phát hiện nhanh bất thường, chuẩn hóa biến số và loại bỏ dữ liệu lỗi.
Bên cạnh đó, khả năng xây dựng do-file cho phép doanh nghiệp tái sử dụng quy trình làm sạch, chuẩn hóa pipeline và giảm phụ thuộc vào thao tác thủ công. Dữ liệu sạch cũng giúp rút ngắn thời gian phân tích, tối ưu nguồn lực và tăng tính minh bạch nhờ khả năng truy vết quá trình xử lý. Sau khi chuẩn hóa, dữ liệu từ Stata còn có thể tích hợp linh hoạt với Python hay R, tạo nền tảng cho các mô hình nâng cao và tự động hóa.
Tăng độ chính xác, giảm rủi ro sai lệch trong mô hình
Chuẩn hóa quy trình, tiết kiệm chi phí và nâng cao hiệu suất phân tích
Hạn chế khi làm sạch dữ liệu trong Stata
– Phụ thuộc mạnh vào tư duy dòng lệnh (command-driven paradigm): Không giống các công cụ GUI, Stata yêu cầu người dùng hiểu rõ logic xử lý dữ liệu theo từng bước. Sai một lệnh nhỏ (ví dụ điều kiện if) có thể làm biến đổi toàn bộ dataset mà không dễ nhận ra ngay.
– Tính thủ công vẫn cao trong các kịch bản phức tạp: Với dữ liệu nhiều nguồn, nhiều định dạng (Excel, CSV, database), việc:
import
chuẩn hóa schema
xử lý ngoại lệ thường phải viết tay từng bước → khó scale nếu không có chuẩn nội bộ.
– Khả năng xử lý dữ liệu lớn (big data) còn hạn chế: So với Python (pandas, PySpark) hay R (data.table): Stata phụ thuộc nhiều vào RAM, không tối ưu cho dữ liệu hàng chục triệu dòng trở lên
– Đường cong học tập dốc với người không có nền tảng kỹ thuật: Người mới phải nắm: cú pháp, logic dữ liệu, cấu trúc lệnh,…
– Hạn chế trong tự động hóa nâng cao và tích hợp hệ thống: Stata có thể scripting, nhưng:
khó tích hợp CI/CD
không mạnh trong orchestration pipeline (so với Airflow, Python ecosystem)
Làm sạch dữ liệu chuyên sâu với phần mềm BCanvas
Điều mà các nhà quản trị thực sự quan tâm chính là: làm thế nào để làm sạch dữ liệu, chuẩn hoá và biến nó thành nền tảng tin cậy cho các quyết định chiến lược. Đây chính là khoảng trống mà phần mềm BCanvas xử lý và phân tích dữ liệu kinh doanh tích hợp AI được thiết kế để lấp đầy.
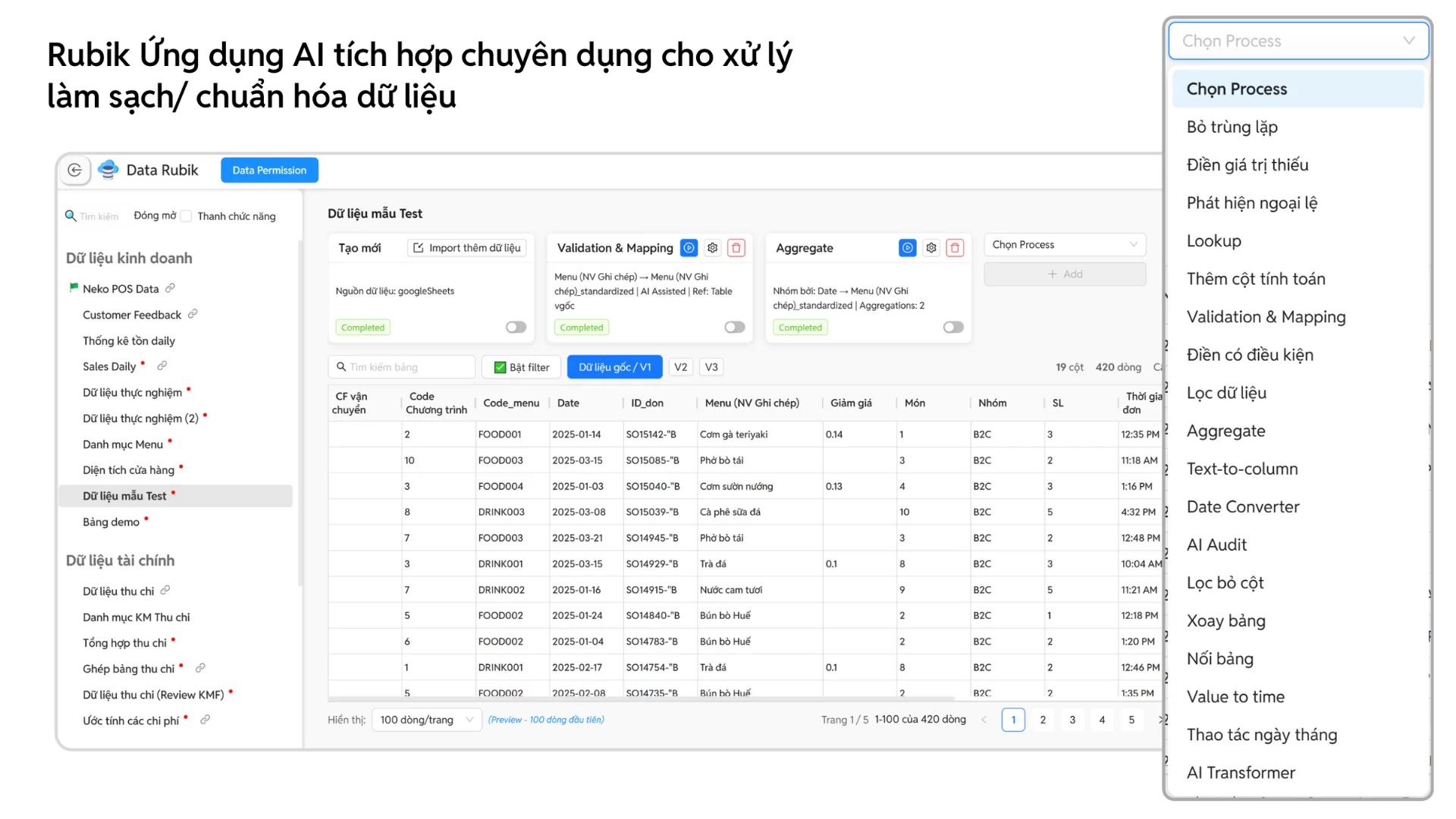
Điểm đột phá nằm ở tính năng Data Rubik. Không chỉ dừng lại ở khả năng xử lý bảng tính như Excel, Data Rubik được tích hợp AI để audit dữ liệu một cách tự động: phát hiện và loại bỏ trùng lặp, sửa lỗi định dạng, chuẩn hoá đơn vị đo lường, thậm chí cảnh báo bất thường trong dữ liệu giao dịch. Nhờ vậy, doanh nghiệp có thể xây dựng được một nguồn dữ liệu sạch, thống nhất và tin cậy.
BCanvas còn có khả năng tạo mới hoặc ghi đè dữ liệu lên Google Sheet một cách tự động – tính năng hiện không khả dụng trong Power Query của Power BI, giúp đội ngũ kế toán hoặc nhân sự có thể dễ dàng cập nhật báo cáo mà không cần thao tác thủ công.
Một điểm mạnh khác là chế độ Auto Run: khi dữ liệu nguồn thay đổi (ví dụ file Excel hoặc Google Sheet được cập nhật), hệ thống sẽ tự động đồng bộ và làm mới dữ liệu trên dashboard. Nhờ đó, người dùng luôn theo dõi được số liệu mới nhất mà không cần can thiệp kỹ thuật.
Ngoài ra, khả năng kết nối và hợp nhất dữ liệu của BCanvas được tối ưu để đồng bộ tức thì với các phần mềm phổ biến tại Việt Nam như phần mềm kế toán, hệ thống POS, Excel, Google Sheets hay dữ liệu marketing từ mạng xã hội.
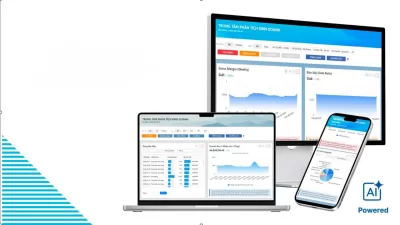
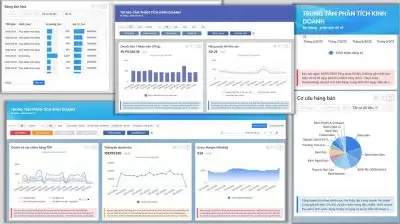
Dữ liệu sau khi được xử lý – làm sạch – chuẩn hoá (từ nhiều nguồn, loại bỏ trùng lặp, sai định dạng và tự động đối chiếu) tại Data Rubik, Công cụ Phân tích kinh doanh sẽ nhặt các chỉ số cụ thể từ KPI Map để chuyển dữ liệu thành hệ thống KPI động, phản ánh trung thực sức khoẻ của doanh nghiệp qua từng cấp độ phân tích: chiến lược – vận hành – bộ phận.
Thiết lập bộ KPI chiến lược: Doanh nghiệp có thể xây dựng bộ chỉ số gắn liền với mục tiêu dài hạn – ví dụ: tăng trưởng doanh thu, tối ưu biên lợi nhuận, hoặc nâng cao năng suất đội ngũ. Mỗi KPI được cập nhật tự động từ nguồn dữ liệu đã chuẩn hóa, đảm bảo tính nhất quán và độ tin cậy tuyệt đối.
Phân tích KPI đa chiều: Nhà quản trị có thể xem, so sánh và phân tích hiệu suất theo sản phẩm, khu vực, kênh bán hoặc nhóm khách hàng. Hệ thống AI tự động phát hiện các mối tương quan, gợi ý insight và cảnh báo bất thường – giúp người lãnh đạo không chỉ “biết chuyện gì đang xảy ra”, mà còn “hiểu vì sao nó xảy ra”.
Tất cả được trình bày trong dashboard trung tâm KPI, nơi mọi chỉ số then chốt – từ doanh thu, chi phí, lợi nhuận đến tỷ suất hiệu quả – được đồng bộ tự động. Thay vì tốn hàng giờ tổng hợp thủ công, nhà quản trị có thể nhìn thấy bức tranh hiệu suất toàn doanh nghiệp trong vài phút, theo dõi tiến độ đạt KPI, so sánh hiệu quả giữa các đơn vị kinh doanh và ra quyết định kịp thời để tối ưu biên lợi nhuận.