Xử lý dữ liệu (data processing) – một công đoạn từng bị xem là kỹ thuật hậu trường – đang trở thành trung tâm trong quá trình chuyển đổi chiến lược của doanh nghiệp hiện đại. Một làn sóng chuyển dịch âm thầm nhưng sâu sắc đang định hình lại cách các tổ chức thu thập, phân tích và khai thác dữ liệu. Khi dữ liệu không ngừng bùng nổ, xử lý dữ liệu cần gắn với phân tích dữ liệu, quản trị dữ liệu, đo lường chất lượng dữ liệu và tích hợp dữ liệu để tạo ra giá trị kinh doanh thực sự.
Không còn là thao tác kỹ thuật đơn lẻ, xử lý dữ liệu ngày nay đóng vai trò then chốt trong việc nâng cao năng lực ra quyết định, tăng khả năng thích nghi và tạo dựng lợi thế cạnh tranh trong môi trường số. Theo dự báo của IDC (thông qua Network World), khối lượng dữ liệu toàn cầu sẽ đạt 175 zettabyte vào năm 2025, tăng hơn 5 lần chỉ trong vòng 7 năm.
Điều này đặt ra một thách thức chưa từng có: làm sao để xử lý dữ liệu không chỉ nhanh, mà còn thông minh, có ngữ cảnh và hướng hành động?
Trong nhiều doanh nghiệp, xử lý dữ liệu vẫn bị giới hạn trong một vòng tuần hoàn cũ: thu thập – làm sạch – tổng hợp – lưu trữ. Quy trình này thường thủ công, tách biệt giữa các bộ phận, và chủ yếu phục vụ cho các báo cáo mang tính hậu kiểm. Nhưng trong môi trường vận hành theo thời gian thực và cạnh tranh bằng tốc độ, cách tiếp cận cũ đó không còn đủ.
Doanh nghiệp ngày nay phải đối mặt với lượng dữ liệu khổng lồ, đa định dạng – từ video, âm thanh, cảm biến IoT đến văn bản phi cấu trúc – đổ về từ nhiều nguồn phân tán. Không chỉ cần xử lý nhanh, họ còn phải chuyển hóa dữ liệu ấy thành hành động ngay tức thì. Điều này đặt ra yêu cầu cho một kiến trúc xử lý hiện đại: xử lý song song, phân tán, tích hợp AI để đưa dữ liệu về đúng bối cảnh kinh doanh.
Trong hệ sinh thái dữ liệu hiện đại, xử lý dữ liệu không chỉ nhằm “làm sạch” mà để hiểu – lý giải – và dẫn đường cho hành động. Từ một luồng dữ liệu chưa qua xử lý, doanh nghiệp cần trả lời ba câu hỏi cốt lõi: chuyện gì đang xảy ra, vì sao lại xảy ra, và chúng ta nên làm gì tiếp theo.
Cốt lõi của xử lý dữ liệu hiện đại không nằm ở công nghệ, mà ở tư duy dữ liệu: khả năng thiết kế quy trình ra quyết định xoay quanh dữ liệu, xác định đúng đâu là dữ liệu quan trọng, và xây dựng hệ thống để xử lý đúng thời điểm, đúng ngữ cảnh, đúng mục tiêu.
Chuyển đổi này đòi hỏi sự hợp lực sâu sắc giữa các bên: IT – phân tích dữ liệu – vận hành – tài chính – lãnh đạo cấp cao. Khi đó, xử lý dữ liệu sẽ không còn là một công việc mang tính kỹ thuật đơn lẻ, mà trở thành một nền tảng chiến lược, giúp doanh nghiệp mô hình hóa tương lai, dự báo rủi ro, tối ưu vận hành và nâng cao trải nghiệm khách hàng một cách chủ động.
Như TacaSoft chia sẻ, một trong những thay đổi âm thầm nhưng sâu sắc nhất của thời đại dữ liệu là: các nền tảng, quy trình và tư duy xử lý dữ liệu hiện tại đang không còn theo kịp tốc độ và hình thái thay đổi của dữ liệu. Trong nhiều năm, doanh nghiệp đã xây dựng hệ thống xung quanh những loại dữ liệu có cấu trúc, ổn định và được sinh ra theo chu kỳ rõ ràng.
Dữ liệu đang phát sinh ở mọi nơi – từ cảm biến, video, giọng nói, tín hiệu giao dịch đến dữ liệu văn bản phi cấu trúc – và đến từ những nguồn không đồng nhất, theo thời gian thực.
Tuy nhiên, phần lớn cơ sở hạ tầng dữ liệu hiện có vẫn được thiết kế theo mô hình cũ, phục vụ cho một loại dữ liệu cụ thể tại một thời điểm cụ thể. Việc cố gắng “vá víu” bằng cách tích hợp các công cụ không đồng bộ chỉ dẫn đến hệ thống dễ bị tắc nghẽn khi quy mô tăng lên.
>> Khuyến nghị: Chúng ta đang cần một cách tiếp cận hoàn toàn mới – không phải là mở rộng cái cũ, mà là thiết kế lại từ đầu để phù hợp với thực tế mới của dữ liệu.
Ở cấp độ vận hành, các tình huống kinh doanh hiện nay đòi hỏi sự hội tụ đa dạng của dữ liệu – cả về định dạng lẫn thời gian.
Ví dụ: để giám sát một quy trình sản xuất theo thời gian thực, doanh nghiệp cần kết hợp dữ liệu từ máy móc (IoT), văn bản kỹ thuật, giọng nói từ trung tâm điều hành, thậm chí là video AI phát hiện lỗi. Tất cả phải được xử lý tức thì, có khả năng dự đoán, và phản hồi nhanh chóng – không chỉ ở cấp độ trung tâm (cloud), mà ngay cả tại rìa mạng (edge) nơi dữ liệu được sinh ra.
Thách thức cốt lõi nằm ở việc: phá vỡ các silo giữa các bộ phận, giữa các hệ thống, và giữa các cách tiếp cận cũ – để tạo ra một không gian xử lý hội tụ, nơi dữ liệu được “sống” và được kích hoạt ngay trong dòng chảy kinh doanh. Chỉ khi đó, xử lý dữ liệu mới không còn là trở ngại kỹ thuật, mà trở thành một lợi thế cạnh tranh thực sự.
Chu trình xử lý dữ liệu bao gồm một loạt các bước, trong đó dữ liệu thô (đầu vào) đưa vào hệ thống tạo ra thông tin chi tiết hỗ trợ hành động (đầu ra). Mỗi bước được thực hiện theo một thứ tự cụ thể, nhưng toàn bộ quá trình sẽ lặp lại theo chu kỳ.
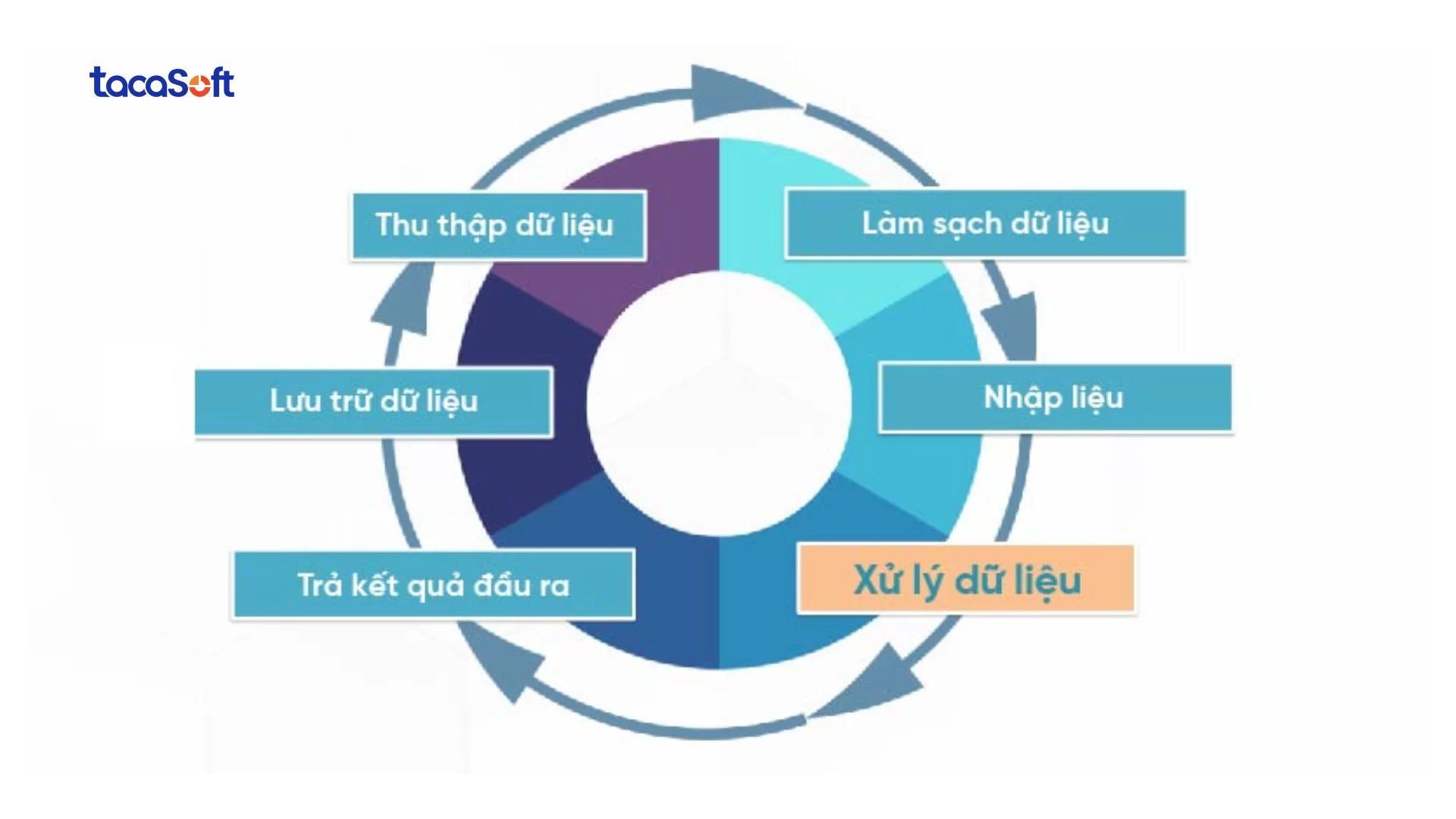
Trong chu trình xử lý dữ liệu, thu thập đầu vào không chỉ là bước khởi đầu – mà là nền móng quyết định độ tin cậy, hiệu lực và khả năng ứng dụng của toàn bộ hệ thống phân tích. Chất lượng của dữ liệu thô chính là giới hạn trên của chất lượng insight mà doanh nghiệp có thể khai thác.
Không phải mọi dữ liệu đều có giá trị như nhau. Doanh nghiệp cần xác định rõ nguồn gốc, tính pháp lý, độ chính xác và tính liên quan của dữ liệu thô trước khi đưa vào quy trình xử lý. Điều này đặc biệt quan trọng khi dữ liệu đến từ nhiều nguồn phân tán. Xử lý dữ liệu là phương pháp thu thập dữ liệu thô và dịch nó thành thông tin có thể sử dụng được.
Ngoài ra, việc thu thập cần phải tính đến ngữ cảnh phát sinh dữ liệu: cùng một số liệu có thể mang ý nghĩa hoàn toàn khác nhau tùy thuộc vào thời điểm, địa điểm, mục tiêu kinh doanh hoặc điều kiện thị trường. Nếu không được chú thích đầy đủ hoặc đồng bộ với các hệ thống liên quan, dữ liệu đó rất dễ bị hiểu sai – và dẫn đến những phân tích sai lệch.
Trong các hệ thống hiện đại, việc thu thập không còn là một tác vụ tĩnh, một lần – mà là một dòng chảy liên tục (data stream). Doanh nghiệp không chỉ cần “lấy dữ liệu về”, mà còn phải xây dựng hạ tầng tiếp nhận linh hoạt, có thể xử lý cả dữ liệu theo lô lẫn theo thời gian thực (real-time).
Ngay cả những nguồn dữ liệu được thu thập cẩn thận nhất cũng thường chứa nhiều “tạp chất”: dữ liệu bị thiếu, sai định dạng, dư thừa, trùng lặp hoặc không nhất quán. Chính vì vậy, bước chuẩn bị dữ liệu đảm bảo rằng chỉ những dữ liệu đủ chất lượng mới được đưa vào hệ thống phân tích và ra quyết định.
Ở cấp độ kỹ thuật, chuẩn bị dữ liệu bao gồm các công việc như:
Tuy nhiên, điều quan trọng hơn cả là tư duy tiếp cận với bước này: chuẩn bị dữ liệu là bước đầu tiên để “đưa dữ liệu về đúng bối cảnh kinh doanh”. Một số dữ liệu tưởng như không sai về mặt kỹ thuật, nhưng lại hoàn toàn vô nghĩa trong một ngữ cảnh kinh doanh cụ thể (ví dụ: số liệu chưa cập nhật biến động giá nguyên liệu, hoặc không tính đến thay đổi chính sách chiết khấu).
Sau khi dữ liệu đã được thu thập và làm sạch, bước tiếp theo là chuyển đổi chúng thành định dạng mà hệ thống máy tính có thể hiểu, lưu trữ và xử lý. Đây là giai đoạn “số hoá thực thi” – nơi dữ liệu bắt đầu được tích hợp vào luồng xử lý tự động, sẵn sàng cho các bước phân tích, dự đoán và ra quyết định sau đó.
Nhập liệu (data input) ngày nay không còn đơn thuần là việc gõ tay qua bàn phím như trước kia. Với sự phát triển của công nghệ và yêu cầu về tốc độ, độ chính xác và khả năng xử lý khối lượng lớn, việc nhập liệu đang diễn ra thông qua nhiều hình thức:
Tự động hoá bằng API và phần mềm tích hợp: dữ liệu từ phần mềm kế toán, ERP, CRM, hệ thống bán hàng,… có thể được đẩy tự động vào kho dữ liệu hoặc nền tảng phân tích mà không cần thao tác thủ công.
Thiết bị đầu cuối và IoT: trong các doanh nghiệp sản xuất hoặc logistics, dữ liệu có thể đến trực tiếp từ cảm biến, máy đo, camera, hoặc thiết bị di động của nhân viên.
Một yếu tố then chốt trong bước nhập liệu là đảm bảo tính toàn vẹn và đồng bộ của dữ liệu – đặc biệt khi dữ liệu được nhập từ nhiều nguồn, nhiều thời điểm và bởi nhiều người. Một lỗi nhỏ trong cấu trúc dữ liệu đầu vào có thể làm “gãy” toàn bộ chuỗi phân tích phía sau hoặc đưa ra kết quả sai lệch.
Tùy theo mục đích sử dụng và đặc điểm dữ liệu, quá trình xử lý có thể diễn ra theo nhiều phương pháp khác nhau – từ xử lý hàng loạt (batch processing) cho các tập dữ liệu lớn đến xử lý thời gian thực (real-time/stream processing) cho các tình huống yêu cầu phản hồi ngay lập tức.
Một số kỹ thuật thường được áp dụng bao gồm:
Chuẩn hóa và biến đổi dữ liệu (data transformation): giúp đồng bộ dữ liệu từ nhiều nguồn và chuẩn bị cho phân tích sâu hơn.
Phân tích chẩn đoán: trả lời câu hỏi “vì sao điều đó xảy ra?” bằng cách truy tìm mối quan hệ giữa các biến số.
Ứng dụng trí tuệ nhân tạo (AI) và học máy (ML): dùng các mô hình để nhận diện mẫu, phát hiện bất thường, phân khúc khách hàng, dự báo hành vi, hoặc đưa ra khuyến nghị tự động.
Một yếu tố không thể thiếu trong bước này là khả năng mở rộng: doanh nghiệp cần đảm bảo rằng hệ thống xử lý có thể phát triển song song với sự gia tăng của khối lượng và tốc độ dữ liệu. Điều này thường đòi hỏi kiến trúc xử lý phân tán, kết hợp với khả năng tự động hoá và tối ưu hoá hiệu suất theo thời gian thực.
Đầu ra (output) có thể mang nhiều hình thức, tuỳ vào nhu cầu người dùng và mục tiêu sử dụng: biểu đồ trực quan, bảng tổng hợp, dashboard tương tác, file CSV, tài liệu PDF, cảnh báo thời gian thực, âm thanh, video, hoặc thậm chí là đầu vào cho một hệ thống khác
Nhưng điều quan trọng hơn không nằm ở định dạng, mà ở tính sẵn sàng và khả năng hành động:
Lưu trữ dữ liệu không chỉ là “đặt dữ liệu vào một nơi an toàn” – đó là bước quyết định khả năng tái sử dụng, mở rộng phân tích, và bảo toàn tri thức dữ liệu cho doanh nghiệp về lâu dài.
Tại bước này, dữ liệu đầu ra cùng siêu dữ liệu (metadata) – bao gồm thời gian, nguồn gốc, quyền truy cập, trạng thái xử lý… – được ghi nhận và lưu trữ trong hệ thống. Việc lưu trữ cần đảm bảo:
Hiện nay, doanh nghiệp có thể lựa chọn nhiều hình thức lưu trữ: từ kho dữ liệu cho đến các hệ thống lưu trữ đám mây phân tán – tùy theo đặc điểm, tần suất truy cập và mục tiêu khai thác của dữ liệu.
Xử lý dữ liệu thủ công là hình thức nguyên sơ nhất trong chuỗi tiến hóa của dữ liệu – nơi con người đóng vai trò trung tâm trong toàn bộ quá trình: từ thu thập, làm sạch, tính toán đến tổng hợp. Không có phần mềm tự động, không hệ thống hóa, không công nghệ hỗ trợ.
Ở một số môi trường đặc thù, phương pháp này vẫn tồn tại do chi phí công nghệ cao hoặc thói quen vận hành cũ kỹ. Tuy nhiên, trong bối cảnh dữ liệu ngày càng đa dạng, phân tán và phát sinh theo thời gian thực, xử lý thủ công đã trở thành rào cản lớn cho năng suất, chất lượng và khả năng ra quyết định chiến lược.
Dù chi phí công cụ ban đầu thấp, phương pháp này đi kèm với những cái giá ẩn:
Trong thời đại dữ liệu vận hành như dòng chảy, năng lực xử lý chính là năng lực cạnh tranh. Việc tiếp tục phụ thuộc vào phương pháp thủ công không chỉ làm chậm doanh nghiệp, mà còn khiến dữ liệu – tài sản giá trị nhất – trở thành gánh nặng thay vì lợi thế chiến lược.
Xử lý dữ liệu điện tử là phương pháp hiện đại nhất – nơi dữ liệu được tự động hóa toàn phần bằng các phần mềm chuyên biệt, công cụ phân tích và nền tảng công nghệ. Một hệ thống các quy tắc được thiết lập để phần mềm xử lý dữ liệu một cách logic, nhanh chóng và chính xác.
Đây là phương pháp có chi phí đầu tư ban đầu cao nhất, nhưng đổi lại, nó cung cấp:
Trong đời sống và kinh doanh hiện nay, xử lý dữ liệu điện tử đã trở thành một hoạt động “ẩn” nhưng đóng vai trò cốt lõi, diễn ra liên tục trong mọi hệ thống hiện đại. Dưới đây là một số ví dụ thực tế:
Điều đáng lưu ý là: xử lý dữ liệu điện tử không chỉ là một lựa chọn công nghệ – nó là một phần không thể thiếu của chiến lược số hóa. Khi doanh nghiệp bước vào giai đoạn khai thác dữ liệu như một tài sản chiến lược, khả năng xử lý có kiểm soát chính là yếu tố phân tách giữa một tổ chức “phản ứng” và một tổ chức “dẫn dắt”.
Nhưng dù AI có thể hỗ trợ làm sạch dữ liệu tốt đến đâu, giá trị thật sự chỉ được tạo ra khi dữ liệu được đưa vào vận hành – cụ thể là qua các hệ thống báo cáo, phân tích.
>> Tham khảo dòng giải pháp phần mềm phân tích kinh doanh BCanvas giải quyết triệt để những rào cản khiến doanh nghiệp gặp khó khăn khi triển khai Hệ thống báo cáo quản trị, biến dữ liệu doanh nghiệp thành sức mạnh cạnh tranh – đảm bảo doanh nghiệp không chỉ làm chủ hoàn toàn được Hệ thống quản trị và dữ liệu của mình.
Với BCanvas, dữ liệu doanh nghiệp không còn là những bảng tính chắp vá, mà được biến thành lợi thế cạnh tranh rõ ràng: giúp CEO và đội ngũ lãnh đạo làm chủ hoàn toàn hệ thống quản trị và dữ liệu, kể cả khi quy mô doanh nghiệp không ngừng mở rộng. Quan trọng hơn, đây không chỉ là công cụ để “kiểm soát hiện tại”, mà là nền tảng để khẳng định tầm nhìn chiến lược khác biệt và năng lực ra quyết định vượt trội.
BCanvas hỗ trợ ra quyết định nhanh, chính xác và liền mạch – tất cả dựa trên dữ liệu thực tế. Bạn có thể giám sát các chỉ số vận hành, KPI, quản trị tài chính và hiệu suất đội nhóm một cách tự động, toàn diện – thay vì mất thời gian tổng hợp, đội ngũ của bạn có thể dành toàn lực cho chuyên môn cốt lõi, chỉ trong vài cú nhấp chuột.
Tương lai của xử lý dữ liệu không còn xoay quanh công nghệ đơn lẻ, mà là sự hội tụ của điện toán đám mây, AI và dữ liệu lớn trong một hệ sinh thái vận hành thời gian thực – nơi doanh nghiệp không chỉ “phân tích dữ liệu” mà thực sự vận hành bằng dữ liệu.
Trong quá khứ, xử lý dữ liệu là bài toán hiệu suất: làm sao thu thập – xử lý – lưu trữ một cách trơn tru, chính xác. Nhưng nay, khi lượng dữ liệu phát sinh theo cấp số nhân từ các nền tảng số, cảm biến IoT, video, hành vi người dùng…, thì yêu cầu cốt lõi đã chuyển thành: làm sao phản ứng được với dữ liệu trong khoảnh khắc nó được tạo ra?
Câu trả lời nằm ở điện toán đám mây (cloud computing) – không chỉ là “nơi chứa dữ liệu” mà là hạ tầng xử lý phân tán, linh hoạt, tự mở rộng, cho phép doanh nghiệp:
Đặc biệt, khi phần mềm, hệ thống xử lý và thuật toán liên tục cập nhật – cloud chính là lớp “đệm thích nghi”, giúp doanh nghiệp chuyển đổi công nghệ liền mạch, không gián đoạn vận hành.
Quan trọng hơn cả, điện toán đám mây tái định nghĩa vai trò của xử lý dữ liệu: từ một quy trình hậu kiểm thành một nền tảng chiến lược xuyên suốt toàn tổ chức – kết nối IT, vận hành, tài chính, tiếp thị và cả lãnh đạo cấp cao. Khi dữ liệu không còn bị “cô lập”, thì những quyết định cũng không còn dựa trên cảm tính, mà dựa trên bức tranh toàn cảnh, thời gian thực.
Tương lai của xử lý dữ liệu không chỉ là “nhanh hơn, rẻ hơn” – mà là thông minh hơn, thích nghi hơn và định hướng chiến lược hơn.
Xem thêm:
Xử lý dữ liệu được áp dụng cho rất nhiều lĩnh vực khác nhau, vì vậy, những người học CNTT hay không học vẫn có thể học được ngành này và làm được nhiều mảng khác chứ không chỉ CNTT. Hãy cùng xem một số vị trí công việc hiện nay nhé!
Trên thực tế, có rất nhiều loại xử lý dữ liệu khác nhau, được áp dụng trong nhiều trường hợp khác nhau.
| Phân loại | Cách dùng |
| Xử lý hàng loạt | Dữ liệu được thu thập và xử lý theo lô. Phương pháp này thường áp dụng cho một lượng lớn dữ liệu. |
| Xử lý thời gian thực | Dữ liệu được xử lý trong vòng vài giây ngay sau thao tác nhập liệu. Phương pháp này có thể áp dụng cho dữ liệu quy mô nhỏ. |
| Đa xử lý | Dữ liệu được chia nhỏ thành các khung và được xử lý bằng hai hoặc nhiều CPU trong một hệ thống máy tính. Phương pháp này còn được gọi là xử lý song song. |
| Xử lý trực tuyến | Dữ liệu được tự động đưa vào CPU ngay khi có sẵn. Phương pháp này thường áp dụng để xử lý dữ liệu liên tục. |
| Time-sharing | Phân bổ tài nguyên máy tính và dữ liệu theo thời gian cho nhiều người dùng đồng thời. |
Việc xử lý dữ liệu mang lại rất nhiều lợi ích cho các doanh nghiệp, tổ chức, cụ thể như sau:
TacaSoft,