Tối ưu hiệu năng và bảo mật là hai trụ cột cốt lõi trong cách xử lý dữ liệu khi vận hành các hệ thống xử lý dữ liệu lớn trong SQL Server. Theo nguồn nghiên cứu MoldStud, thực tế cho thấy 60 – 70% vấn đề hiệu năng bắt nguồn từ các truy vấn tối ưu kém, không phải hạ tầng, trong khi lập chỉ mục đúng cách có thể cải thiện hiệu suất lên đến 200%, đặc biệt ở các hệ thống thiên về đọc. Vì vậy, việc thường xuyên phân tích kế hoạch thực thi, lựa chọn hợp lý giữa chỉ mục phân cụm và không phân cụm, cùng với việc tích hợp bảo mật ngay từ thiết kế là yếu tố then chốt, nhất là khi 80% tổ chức từng gặp rò rỉ dữ liệu do biện pháp bảo mật không đầy đủ.
Ở cấp độ chiến lược, xử lý dữ liệu lớn trong SQL Server, công cụ xử lý dữ liệu được lựa chọn và năng lực con người là những yếu tố quyết định trực tiếp đến chất lượng ra quyết định. Cũng theo MoldStud, khoảng 90% doanh nghiệp gặp vấn đề về chất lượng dữ liệu, kéo theo rủi ro sai lệch trong phân tích và hoạch định. Đồng thời, gần 65% chuyên gia cơ sở dữ liệu thừa nhận chưa sẵn sàng trước tốc độ phát triển của công nghệ. Điều này đòi hỏi doanh nghiệp phải thiết lập rõ quyền sở hữu dữ liệu, duy trì các quy trình kiểm soát chất lượng chặt chẽ và đầu tư liên tục vào đào tạo để xây dựng năng lực dữ liệu bền vững.
Để xử lý dữ liệu lớn trong SQL Server hiệu quả vào năm 2026, bạn cần kết hợp tối ưu hóa cấu trúc lưu trữ, chỉ mục và tận dụng các tính năng hiện đại.
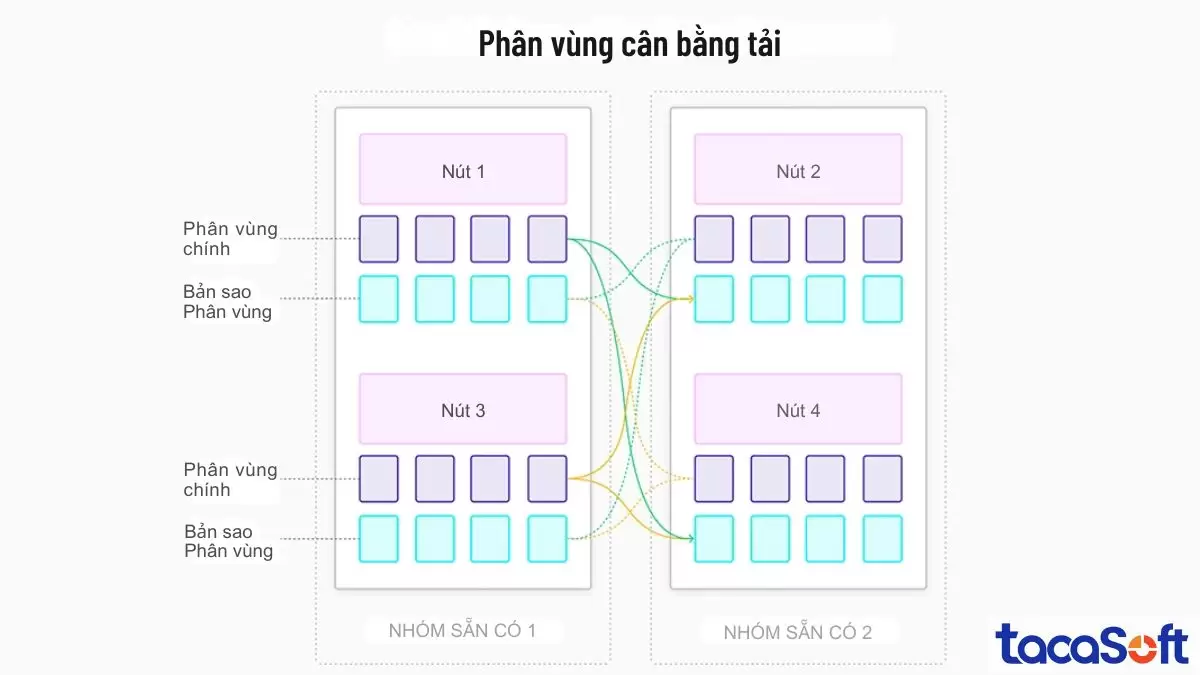
Sơ đồ phân vùng cân bằng tải mô tả cách sắp xếp các phân vùng dữ liệu
Phân mảnh và phân vùng là những kỹ thuật cốt lõi nhằm chia nhỏ tập dữ liệu lớn thành các đơn vị logic dễ quản trị hơn. Dù xử lý dữ liệu lớn trong SQL Server có thể khai thác hàng trăm lõi CPU và bộ nhớ lên đến hàng terabyte, một bảng dữ liệu đơn lẻ vẫn tồn tại giới hạn thực tế về khả năng mở rộng, bảo trì và hiệu năng.
Khi kích thước bảng tăng trưởng không kiểm soát, các thao tác tưởng chừng đơn giản như nạp dữ liệu mới, loại bỏ dữ liệu cũ hay duy trì chỉ mục đều trở thành điểm nghẽn: thời gian xử lý kéo dài, khóa tài nguyên gia tăng và hiệu năng toàn hệ thống suy giảm.
Xử lý dữ liệu lớn trong SQL Server cung cấp cơ chế phân vùng bảng theo chiều ngang, cho phép chia bảng và chỉ mục thành các phân vùng nhỏ hơn, được lưu trữ trên một hoặc nhiều nhóm tệp. Cách tiếp cận này giúp tách biệt dữ liệu theo logic nghiệp vụ (thời gian, khu vực, trạng thái…), từ đó nâng cao khả năng mở rộng và kiểm soát vận hành.
Khi phân vùng được mở rộng trên nhiều máy chủ, mô hình này được gọi là phân mảnh. Lợi ích mang tính chiến lược bao gồm:
Thực hiện các tác vụ bảo trì (xây dựng lại, tái cấu trúc chỉ mục, lưu trữ dữ liệu) trên từng phân vùng thay vì toàn bộ bảng.
Cho phép trình tối ưu hóa truy vấn của SQL Server định tuyến truy vấn đến đúng phân vùng, giảm đáng kể lượng dữ liệu cần quét và chi phí I/O.
Kỹ thuật xử lý dữ liệu lớn trong SQL Server lập chỉ mục không đơn thuần là “tăng tốc truy vấn”, mà là một quyết định ảnh hưởng sâu rộng đến hiệu năng đọc – ghi, khả năng mở rộng và chi phí vận hành. Nhiều nghiên cứu thực tế cho thấy chiến lược lập chỉ mục đúng đắn có thể cải thiện hiệu suất truy vấn lên đến 300%. Một số nguyên tắc triển khai xử lý dữ liệu lớn trong SQL Server mang tính thực chiến:
Sử dụng Query Store hoặc các DMV của xử lý dữ liệu lớn trong SQL Server để phát hiện các truy vấn tiêu tốn nhiều CPU, I/O hoặc có thời gian thực thi kéo dài. Tối ưu chỉ mục mà không dựa trên dữ liệu thực tế thường dẫn đến lãng phí tài nguyên.
Clustered Index: Phù hợp với các cột truy vấn theo phạm vi hoặc theo thứ tự. Đây là nền tảng vật lý của bảng và thường đủ để đảm bảo tính duy nhất nhờ thứ tự sắp xếp.
Nonclustered Index: Hiệu quả cho các cột xuất hiện thường xuyên trong mệnh đề WHERE và JOIN, giúp tăng tốc truy xuất dữ liệu mục tiêu.
Giới hạn số cột trong chỉ mục để giảm dung lượng lưu trữ và chi phí bảo trì. Chỉ mục càng “rộng”, chi phí ghi và cập nhật càng cao.
Sử dụng sys.dm_db_index_usage_stats để đánh giá mức độ sử dụng. Chỉ mục dư thừa không chỉ vô ích mà còn làm giảm hiệu suất ghi, đặc biệt trong các hệ thống OLTP.
Thiết lập fill factor trong khoảng 70–90% giúp cân bằng giữa hiệu suất đọc và ghi. Thực tế cho thấy mức ~80% giúp giảm tình trạng chia trang khi chèn dữ liệu, trong khi vẫn duy trì hiệu năng truy vấn cao.
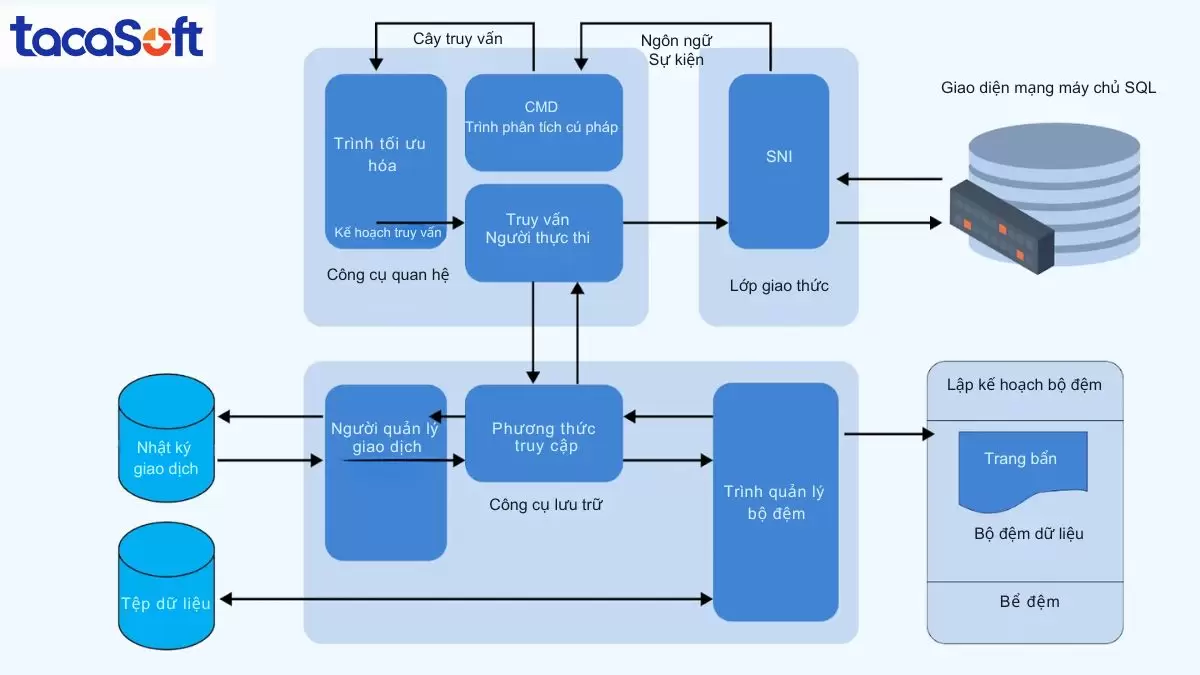
Sơ đồ kiến trúc SQL Server minh họa sự tương tác giữa Relational Engine và Storage Engine
Trong các hệ thống cơ sở dữ liệu quy mô lớn, cách tổ chức dữ liệu quyết định trực tiếp đến khả năng truy cập, mở rộng và bảo vệ dữ liệu về lâu dài. Khi dữ liệu tăng trưởng theo thời gian, nếu không được thiết kế và kiểm soát chặt chẽ, tình trạng dư thừa, trùng lặp và thiếu nhất quán sẽ nhanh chóng phát sinh, gây lãng phí tài nguyên lưu trữ và làm suy giảm hiệu năng truy vấn.
Chuẩn hóa cơ sở dữ liệu là quá trình tái cấu trúc dữ liệu nhằm loại bỏ các bất cập trên, đảm bảo dữ liệu được lưu trữ một cách logic, nhất quán và dễ quản trị. Trong xử lý dữ liệu lớn trong SQL Server, chuẩn hóa giúp giảm thiểu dữ liệu dư thừa, hạn chế lỗi phát sinh trong quá trình cập nhật, đồng thời nâng cao tính linh hoạt khi mở rộng hệ thống. Quá trình này đòi hỏi việc phân tích luồng dữ liệu, mối quan hệ giữa các bảng và cách thức khai thác thông tin, từ đó thiết kế cấu trúc phù hợp với nhu cầu truy vấn thực tế. Dữ liệu có thể được truy xuất hiệu quả thông qua SQL hoặc tích hợp với các ngôn ngữ lập trình như Java, Go, C++, Ruby… để phục vụ các hệ thống nghiệp vụ phức tạp.
Sao lưu dữ liệu trong các cơ sở dữ liệu lớn luôn là một thách thức, đặc biệt khi dung lượng dữ liệu và nhật ký giao dịch tăng nhanh theo thời gian. Sao lưu thường xuyên là yêu cầu bắt buộc để đảm bảo an toàn dữ liệu nhưng nếu triển khai không hợp lý, quá trình này có thể tiêu tốn nhiều tài nguyên và ảnh hưởng đến khả năng vận hành của hệ thống.
Một chiến lược sao lưu hiệu quả cần đảm bảo tính liên tục, khả dụng cao và khả năng khôi phục nhanh. Việc sử dụng nhiều thiết bị sao lưu song song trong xử lý dữ liệu lớn trong SQL Server cho phép ghi dữ liệu đồng thời, giảm đáng kể thời gian sao lưu và tăng độ tin cậy khi xảy ra sự cố. Tương tự, dữ liệu có thể được khôi phục đồng thời từ nhiều nguồn, rút ngắn thời gian phục hồi hệ thống.
Microsoft SQL Server Management Studio cung cấp Maintenance Plan Wizard, cho phép tự động hóa các tác vụ sao lưu, kiểm tra tính toàn vẹn và bảo trì theo lịch trình. Bên cạnh đó, các giải pháp của bên thứ ba có thể được cân nhắc nhằm tối ưu tốc độ sao lưu và giảm dung lượng dữ liệu nén, đặc biệt trong các môi trường doanh nghiệp có yêu cầu khắt khe về thời gian khôi phục (RTO) và mức độ mất dữ liệu cho phép (RPO).
Tối ưu hiệu năng không phải là một nhiệm vụ thực hiện một lần, mà là một quá trình liên tục, đòi hỏi sự giám sát và điều chỉnh đồng bộ trên toàn bộ môi trường xử lý dữ liệu lớn trong SQL Server. Hiệu năng tổng thể của hệ thống chịu ảnh hưởng bởi nhiều yếu tố, bao gồm:
Hạ tầng phần cứng và kiến trúc lưu trữ.
Chất lượng và cấu trúc các truy vấn truy cập dữ liệu.
Chiến lược thiết kế và bảo trì chỉ mục.
Các cấu hình máy chủ và cơ sở dữ liệu.
Phiên bản phần mềm và hệ điều hành đang sử dụng.
Microsoft liên tục giới thiệu các cải tiến hiệu năng trong các phiên bản xử lý dữ liệu lớn trong SQL Server mới. Do đó, việc cập nhật định kỳ SQL Server, hệ điều hành Windows, cùng các thành phần phần cứng và firmware liên quan là yếu tố then chốt để khai thác tối đa các tính năng tối ưu mới nhất. Một môi trường luôn được cập nhật không chỉ cải thiện hiệu suất mà còn nâng cao độ ổn định, bảo mật và khả năng mở rộng của hệ thống trong dài hạn.
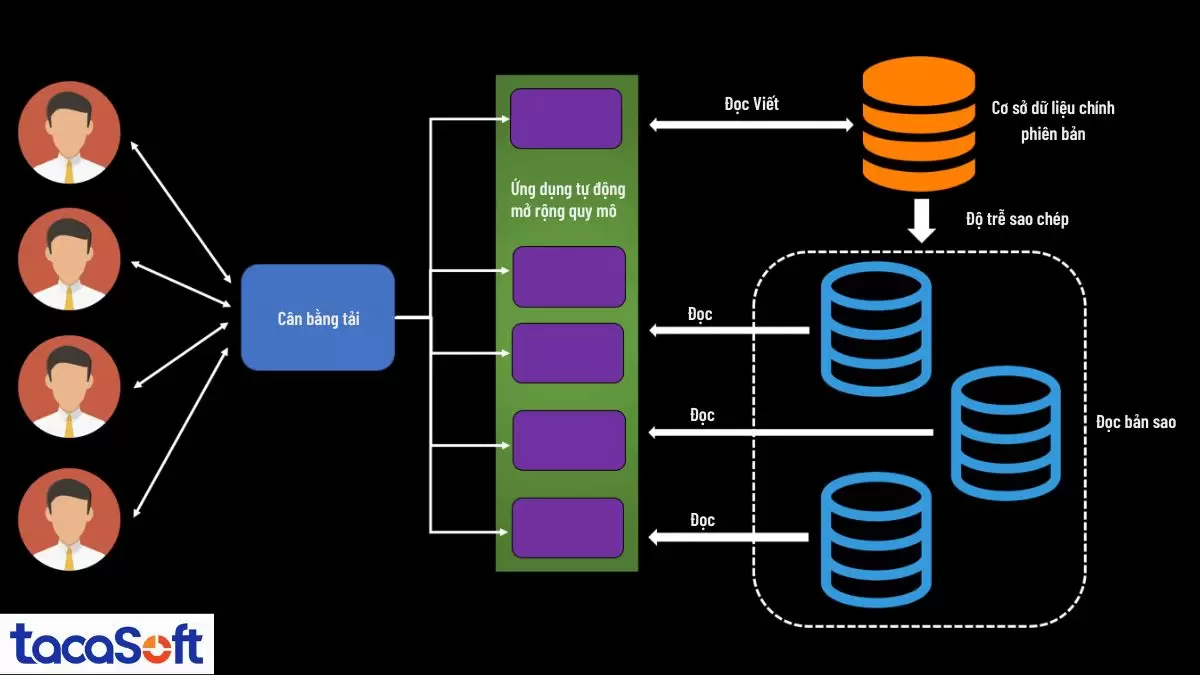
Sơ đồ kiến trúc hệ thống mô tả quy trình điều phối tải và mở rộng cơ sở dữ liệu – Xử lý dữ liệu lớn trong SQL Server
Trong các doanh nghiệp có quy mô dữ liệu lớn, xử lý dữ liệu lớn trong SQL Server thường là trung tâm lưu trữ dữ liệu lõi. Tuy nhiên, thách thức lớn nhất không nằm ở dung lượng dữ liệu, mà ở khả năng kết nối – xử lý – chuẩn hóa – phân tích dữ liệu một cách có kiểm soát. BCanvas được xây dựng để bổ sung một tầng xử lý và phân tích thông minh phía trên SQL Server, giúp doanh nghiệp biến dữ liệu thô thành công cụ ra quyết định.
BCanvas áp dụng mô hình tách biệt rõ ràng giữa hai lớp nghiệp vụ:
Lớp xử lý & chuẩn hóa dữ liệu: Do đội Data/IT phụ trách.
Lớp phân tích & ra quyết định kinh doanh: Do đội Business/Quản trị sử dụng.
Cách tiếp cận này giúp:
Tránh dữ liệu tự động luân chuyển nhưng không có kiểm soát.
Đảm bảo SQL Server luôn là Single Source of Truth.
Phân định rõ trách nhiệm giữa các bộ phận trong doanh nghiệp.
Data Rubik đóng vai trò là lớp Data Preparation & Transformation, giúp giảm tải xử lý dữ liệu lớn trong SQL Server, đồng thời đảm bảo dữ liệu trước khi ghi vào hệ thống phân tích luôn đạt chuẩn.
Khả năng kết nối đa nguồn:
Excel, Google Sheets, Google Drive.
CRM, POS, phần mềm kế toán.
API hệ thống nghiệp vụ.
Trực tiếp với xử lý dữ liệu lớn trong SQL Server và các CSDL khác.
Tự động đồng bộ dữ liệu:
AutoRun tự động cập nhật khi dữ liệu nguồn thay đổi.
Giảm thao tác thủ công, đảm bảo dữ liệu luôn mới và nhất quán.
Data Rubik kế thừa các thao tác quen thuộc của Excel nhưng được thiết kế cho môi trường xử lý dữ liệu lớn trong SQL Server và đa nguồn:
Phát hiện và loại bỏ dữ liệu trùng lặp.
Chuẩn hóa danh mục, mã khách hàng, sản phẩm, đơn vị đo lường.
Xử lý giá trị thiếu, ngoại lệ và dữ liệu bất thường.
Mapping dữ liệu giữa các nguồn khác nhau.
Pivot, aggregate, if–then theo logic nghiệp vụ.
Hệ thống hỗ trợ 3 nhóm xử lý chính:
Xử lý dữ liệu lớn trong SQL Server cơ bản.
Thêm cột tính toán.
Rubik AI – xử lý tự động bằng AI.
Rubik AI giúp dữ liệu không chỉ “đúng” mà còn có ngữ nghĩa và sẵn sàng phân tích:
Chuẩn hóa địa chỉ, tên riêng (ví dụ: “HN”, “Ha Noi” → “Hà Nội”).
Trích xuất dữ liệu có cấu trúc từ dữ liệu phi cấu trúc.
Phân tích cảm xúc, chuyển đổi dữ liệu định tính thành định lượng.
Tự động điền dữ liệu thiếu theo logic AI.
Kết quả là dữ liệu khi đưa vào xử lý dữ liệu lớn trong SQL Server đã sạch, chuẩn và đồng nhất, giảm đáng kể thời gian xử lý ở các bước sau.
KPI Map giúp doanh nghiệp chuyển từ việc “xem số liệu rời rạc” sang hiểu toàn bộ mô hình vận hành:
Xây dựng bản đồ KPI theo từng mô hình kinh doanh.
Thể hiện mối quan hệ nguyên nhân – kết quả giữa các chỉ số.
Chuẩn hóa công thức KPI trên toàn hệ thống.
Cho phép điều chỉnh công thức trực tiếp, không cần xử lý thủ công.
Toàn bộ KPI được liên kết trực tiếp với dữ liệu đã chuẩn hóa trong xử lý dữ liệu lớn trong SQL Server, đảm bảo thống nhất cách hiểu giữa các phòng ban.
Từ KPI Map, người dùng có thể xây dựng các Dashboard theo nhu cầu quản trị:
KPI Card: theo dõi nhanh các chỉ số trọng yếu
Charts: phân tích xu hướng và mối quan hệ
Table Analytics: phân tích bảng dữ liệu chuyên sâu
Comparison: so sánh giữa các kỳ, đơn vị, mô hình
Xử lý dữ liệu lớn trong SQL Server Dashboard được tổ chức theo Balanced Scorecard (BSC):
Tài chính.
Khách hàng.
Vận hành.
Nhân sự.
Khác với phương pháp phân bổ chi phí truyền thống, BCanvas cho phép:
Phân bổ chi phí và doanh thu theo từng dòng nhật ký kế toán trong xử lý dữ liệu lớn trong SQL Server.
Gắn trực tiếp chi phí với dự án, sản phẩm, phòng ban hoặc khách hàng.
Truy vết đầy đủ nguồn gốc hình thành doanh thu và lãi/lỗ.
Cách tiếp cận xử lý dữ liệu lớn trong SQL Server này giúp:
Phản ánh đúng bản chất hiệu quả tài chính.
Tăng tính minh bạch và công bằng nội bộ.
Nâng cao độ tin cậy của các chỉ số KPI, ROI, ROE.
Xử lý dữ liệu lớn trong SQL Server BCanvas tích hợp AI Chat giúp nhà quản trị:
Hỏi – đáp trực tiếp về các KPI và Dashboard.
Phân tích nguyên nhân biến động.
Gợi ý hướng tối ưu dựa trên dữ liệu lịch sử.
Nhà quản trị không chỉ “xem dữ liệu”, mà thực sự khai thác tri thức từ dữ liệu.
Phần mềm BCanvas xử lý và phân tích dữ liệu kinh doanh tích hợp AI
Đăng ký trải nghiệm BCanvas ngay hôm nay dành riêng cho mô hình kinh doanh của bạn!
Nhận tư vấn toàn bộ tính năng phần mềm được thiết kế riêng cho doanh nghiệp bạn với sự tư vấn, đồng hành từ đội ngũ chuyên gia chuyên môn sâu.