Làm sạch dữ liệu bằng Python là cách hữu dụng giúp doanh nghiệp loại bỏ các lỗi định dạng, giá trị bất thường hoặc dữ liệu không thể sử dụng trong phân tích. Trong thực tế, để trả lời câu hỏi “phương pháp làm sạch dữ liệu nào là phổ biến nhất?” cần xoay quanh hai hướng: xóa bỏ các hàng bị lỗi và chuẩn hóa dữ liệu về cùng một định dạng. Cả hai đều nhằm mục tiêu đảm bảo dữ liệu thống nhất, dễ xử lý, giảm sai sót khi tổng hợp.
Python hỗ trợ rất tốt cho quy trình này nhờ khả năng tự động hóa và thao tác mạnh mẽ trên dữ liệu lớn. Những ô sai định dạng — như số bị lưu dưới dạng text, ngày tháng không đúng chuẩn hoặc dữ liệu chứa ký tự dư thừa — có thể được xử lý nhanh chóng bằng các hàm chuyển đổi, giúp toàn bộ dataset trở nên sạch, đồng nhất và sẵn sàng cho bước phân tích tiếp theo.
Trong dữ liệu thực tế của doanh nghiệp, lỗi định dạng là một trong những vấn đề xuất hiện thường xuyên nhất. Ví dụ phổ biến: cột ngày tháng bị lưu dưới dạng chuỗi không chuẩn, số bị lưu dưới dạng text, hoặc dữ liệu chứa ký tự thừa. Những lỗi nhỏ này có thể khiến Python không đọc được dữ liệu, báo lỗi khi tính toán hoặc làm sai toàn bộ phân tích.
Trường hợp điển hình:
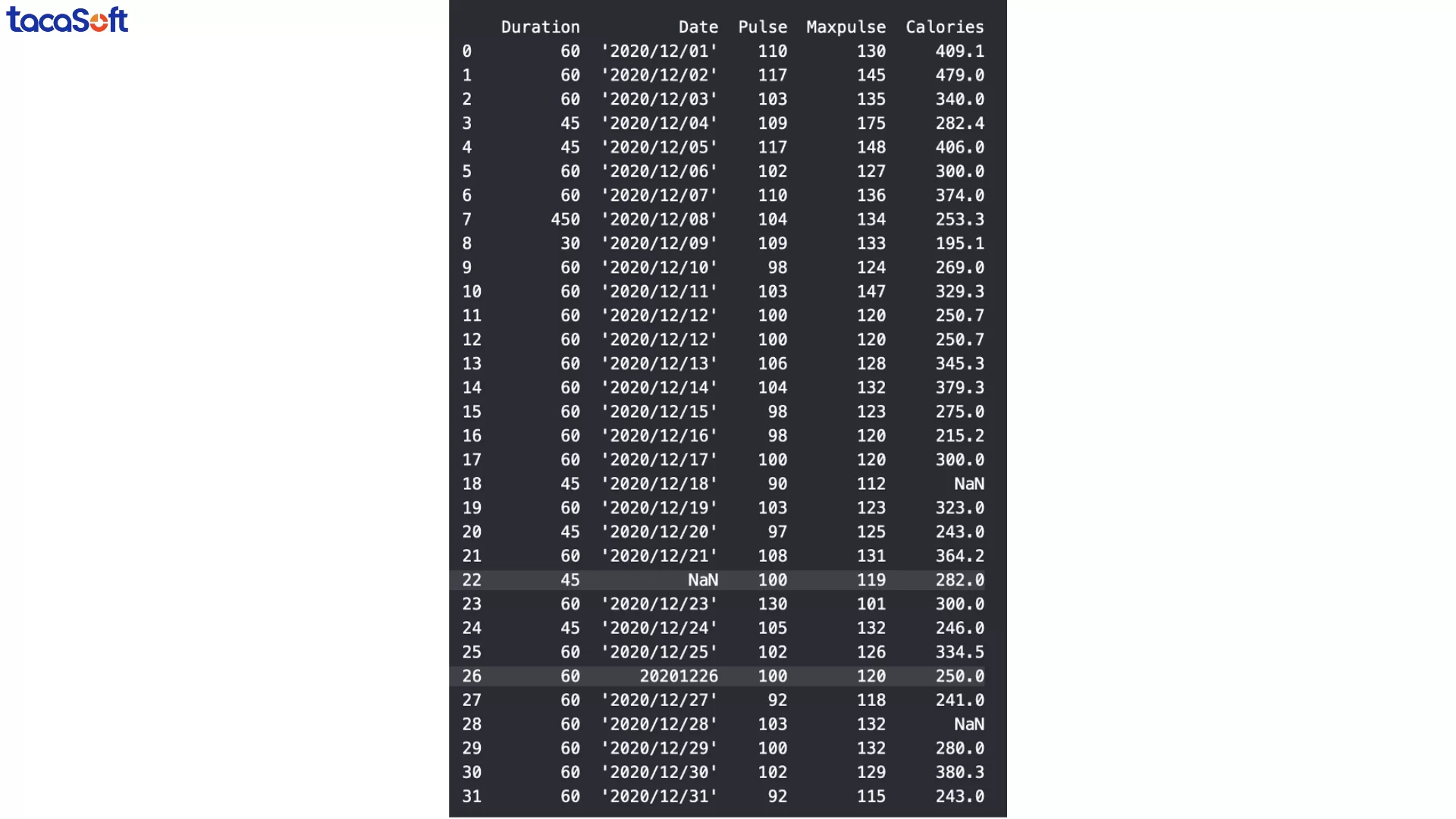
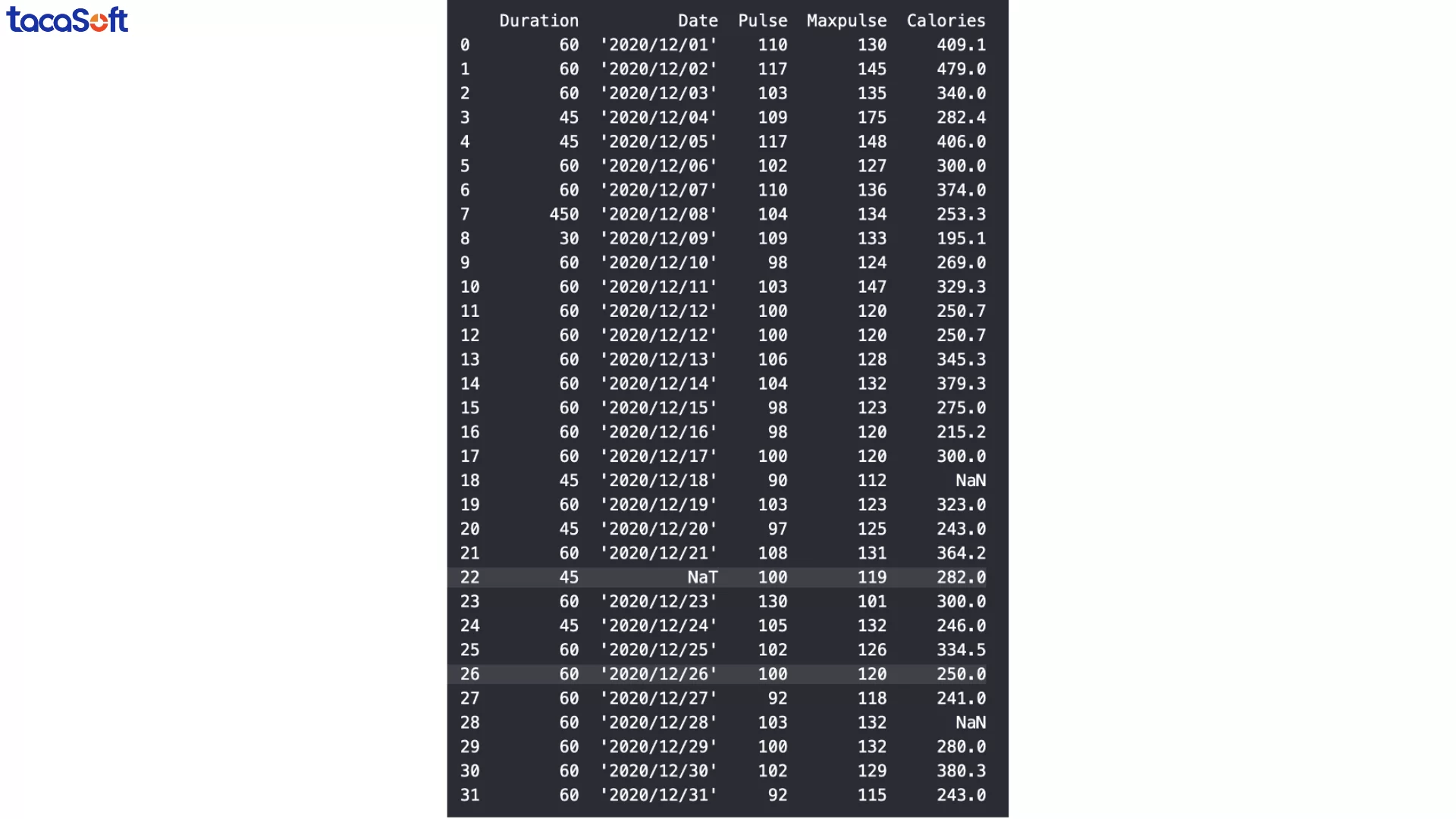
Ở DataFrame mẫu, cột ‘Date’ phải chứa giá trị ngày tháng, nhưng ở một số dòng (ví dụ dòng 22 và 26), dữ liệu lại bị nhập sai định dạng. Điều này khiến việc lọc theo ngày, tính theo tháng, hoặc vẽ biểu đồ thời gian trở nên không thể.
Cách xử lý thực tế bằng Python:
Chuyển toàn bộ cột sang đúng định dạng ngày tháng bằng pd.to_datetime()
Ví dụ mã Python:
Giá trị mang lại cho doanh nghiệp:
Trong dữ liệu thực tế của doanh nghiệp, việc xuất hiện giá trị bị thiếu (NaN) là chuyện rất thường gặp do nhiều nguyên nhân như nhập liệu thiếu, lỗi đồng bộ hệ thống hoặc form dữ liệu chưa chuẩn. Những giá trị trống này dễ khiến Python báo lỗi, làm sai kết quả phân tích và kéo theo báo cáo thiếu chính xác.
Khi xử lý dữ liệu thiếu, có hai nhóm giải pháp phổ biến nhất:
– Xóa dòng chứa giá trị thiếu (dropna())
– Điền giá trị hợp lý (fillna(), SimpleImputer)
Ví dụ thực tiễn:
Trong một số trường hợp, khi chuyển đổi dữ liệu sang định dạng ngày tháng bằng pd.to_datetime(), Python sẽ trả về giá trị NaT (Not a Time). Đây là cách Pandas biểu diễn giá trị NULL cho dữ liệu thời gian. Điều này có nghĩa là dữ liệu ở dòng đó sai định dạng đến mức không thể chuyển đổi.
Tại sao cần xử lý NaT?
Cách xử lý thực tế: Nếu dòng dữ liệu chứa NaT không còn giá trị sử dụng (ví dụ chỉ sai mỗi cột ngày và không thể khôi phục), cách đơn giản và nhanh nhất là loại bỏ dòng đó bằng dropna().
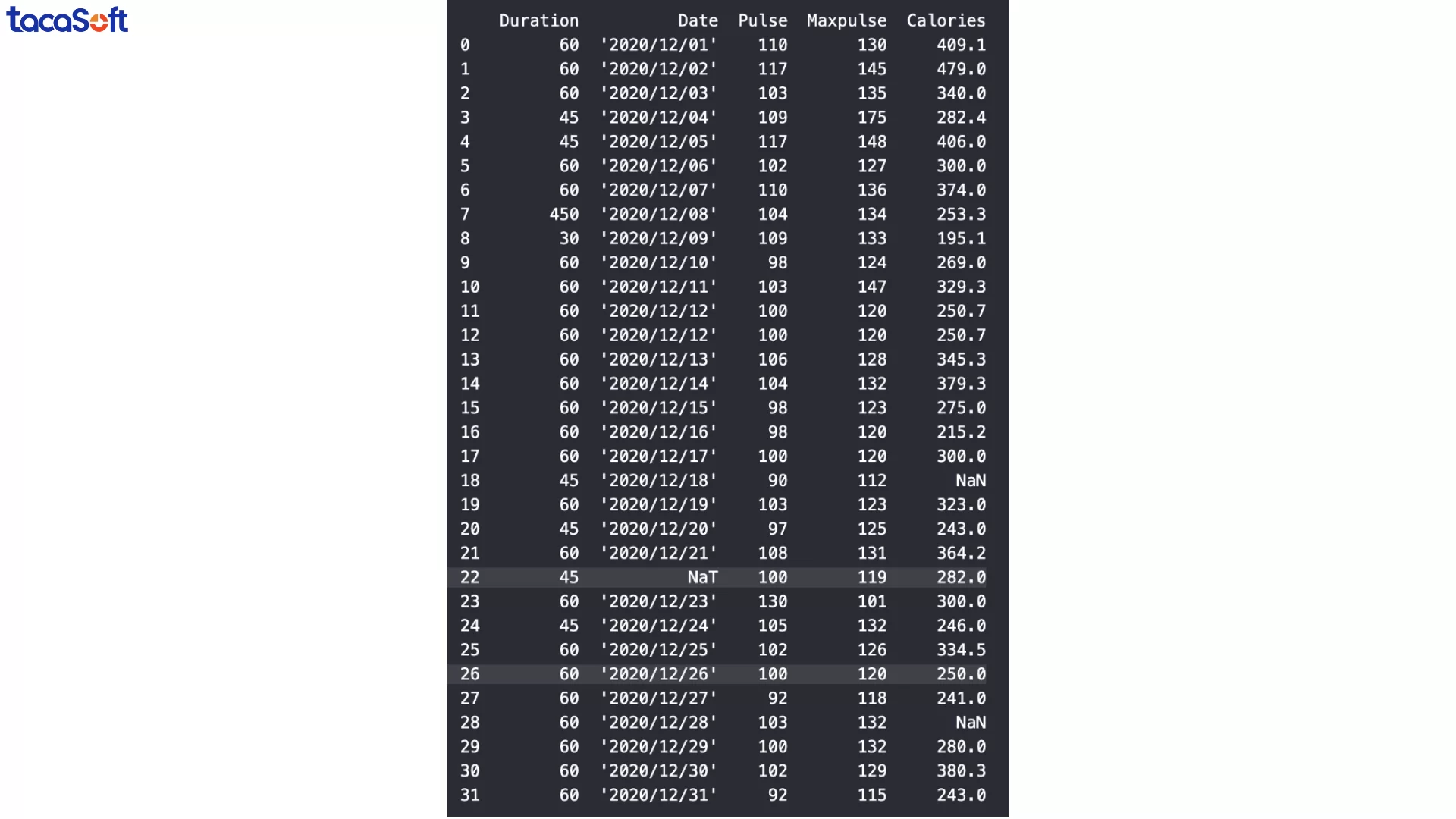
Trong quá trình kiểm tra dữ liệu, đôi khi bạn sẽ phát hiện ra các giá trị bất thường chỉ bằng mắt thường. Ví dụ, trong tập dữ liệu mẫu về thời lượng buổi tập, dòng thứ 7 có giá trị 450 phút, trong khi tất cả các dòng khác chỉ dao động từ 30–60 phút.
Mặc dù không chắc chắn đây là lỗi, nhưng xét về thực tế: không ai có thể tập luyện liên tục 450 phút. Những giá trị như vậy nếu để nguyên sẽ gây sai lệch khi tính trung bình, phân tích xu hướng hay lập báo cáo.
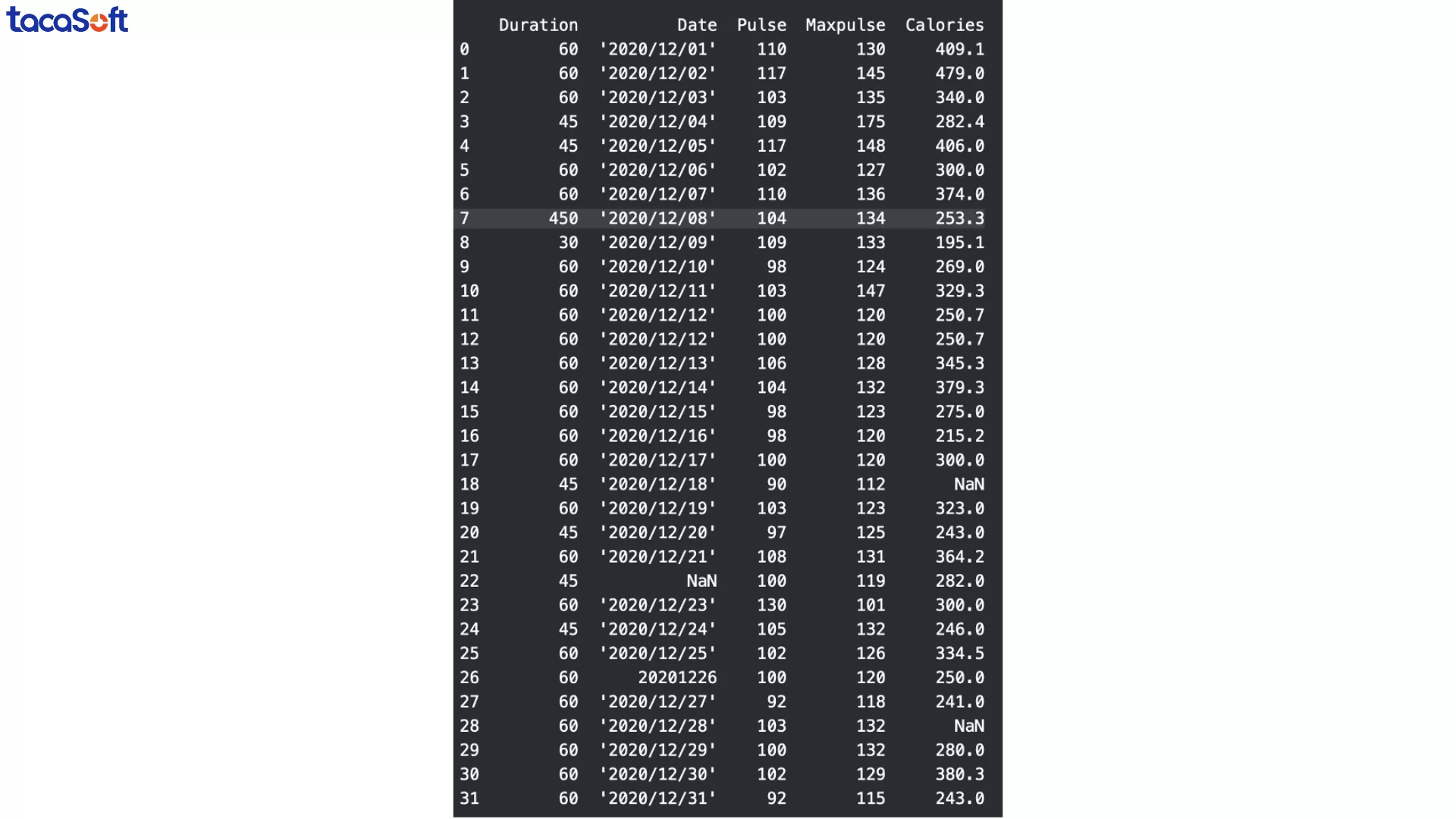
Một cách xử lý các giá trị không chính xác là thay thế chúng bằng một giá trị hợp lý. Trong tập dữ liệu về thời lượng tập luyện, dòng thứ 7 bị ghi nhầm thành 450 phút, trong khi giá trị hợp lý là 45 phút. Ta có thể sửa thủ công như sau: df.loc[7, 'Duration'] = 45 # Thay đổi dữ liệu ở hàng số 7, cột 'Duration'
Lưu ý:
Cách áp dụng quy tắc trên toàn bộ cột:
Duration.Một cách khác để xử lý dữ liệu không chính xác là xóa các hàng chứa giá trị sai.
Khi làm việc với dữ liệu thực tế, bạn sẽ thường gặp một số vấn đề cơ bản sau. Hiểu và xử lý đúng những vấn đề này sẽ giúp phân tích chính xác hơn, giảm rủi ro ra quyết định sai.
1. Các giá trị bị thiếu: Bộ dữ liệu không đầy đủ là chuyện rất thường gặp: thiếu năm dữ liệu, chỉ có một số thông tin về khách hàng, hoặc thiếu dữ liệu sản phẩm. Giá trị bị thiếu (NaN) có thể làm sai lệch kết quả phân tích hoặc phá vỡ mã Python khi chạy các hàm tính toán.
2. Các giá trị ngoại lệ (outliers): Là các giá trị nằm ngoài phạm vi thông thường, có thể do lỗi nhập liệu hoặc tình huống đặc biệt. Ngoại lệ có thể làm sai lệch kết quả, vì vậy cần phân biệt rõ giữa giá trị bất thường thực sự và ngoại lệ do lỗi.
3. Dữ liệu trùng lặp: Các bản ghi trùng lặp có thể làm phân tích bị đại diện quá mức, dẫn đến kết luận sai. Cần cảnh giác với bản sao chứa thông tin mâu thuẫn hoặc cập nhật khác nhau.
4. Dữ liệu sai: Bao gồm lỗi chính tả, số liệu sản phẩm sai, thông tin lỗi thời hoặc nhãn không đúng. Việc xác minh nguồn dữ liệu rất quan trọng, bởi phân tích chỉ tốt khi dữ liệu đúng.
5. Sự không nhất quán: Có thể xuất hiện dưới nhiều hình thức: lỗi đánh máy, thay đổi ID, giá sản phẩm khác nhau cùng lúc. Không nhất quán về đơn vị, định dạng ngày tháng, kiểu dữ liệu hoặc loại tệp cũng khiến phân tích khó thực hiện. Nếu không xử lý, dữ liệu không đồng nhất sẽ làm kết quả sai lệch hoặc khiến mã Python không chạy.
Làm sạch dữ liệu là bước quan trọng trong bất kỳ dự án phân tích dữ liệu hoặc học máy nào. Dữ liệu thô thường chứa giá trị thiếu, ngoại lệ, trùng lặp hoặc sai định dạng. Việc dọn dẹp dữ liệu không chỉ giúp phân tích chính xác hơn mà còn tiết kiệm thời gian, nâng cao hiệu quả ra quyết định cho doanh nghiệp.
Dưới đây là những phương pháp thực tế khi làm sạch dữ liệu bằng Python:
Trước khi loại bỏ hay thay thế dữ liệu, cần hiểu bản chất vấn đề:
Góc nhìn chiến lược: Quyết định cách xử lý (loại bỏ hay thay thế) nên dựa trên mục tiêu phân tích, tỷ lệ dữ liệu bị lỗi và ảnh hưởng đến kết quả kinh doanh. Việc này không chỉ là kỹ thuật mà là bài toán cân nhắc rủi ro – giá trị thông tin.
Mỗi bước làm sạch dữ liệu nên được ghi chú rõ ràng: bạn đã loại bỏ hay sửa những gì, lý do và giả định đi kèm, giúp bạn hoặc đồng nghiệp có thể hiểu và tái sử dụng quy trình, đồng thời giảm rủi ro nhầm lẫn khi dữ liệu được chỉnh sửa nhiều lần.
Một cách hiệu quả để tiết kiệm thời gian và nâng cao chất lượng dữ liệu là xác định những bước làm sạch phổ biến và chuẩn hóa chúng thành quy trình hoặc checklist. Các bước này có thể bao gồm xử lý dữ liệu thiếu, giá trị bất thường, trùng lặp hoặc chuẩn hóa định dạng. Khi được chuẩn hóa, quy trình này có thể áp dụng nhanh cho nhiều bộ dữ liệu khác nhau, đảm bảo tính nhất quán giữa các phân tích và báo cáo.
Đồng thời, việc tái sử dụng quy trình giúp doanh nghiệp duy trì dữ liệu sạch lâu dài, giảm rủi ro sai sót và nâng cao hiệu quả ra quyết định.
Mặc dù làm sạch dữ liệu bằng Python khá mạnh mẽ, nhiều doanh nghiệp gặp phải những rào cản thực tế khi áp dụng. Một trong những vấn đề lớn nhất là phụ thuộc quá nhiều vào thao tác thủ công. Việc xác định, kiểm tra và xử lý từng giá trị thiếu, ngoại lệ hay dữ liệu sai định dạng thường đòi hỏi người dùng phải thao tác từng bước, đặc biệt với các tập dữ liệu lớn.
Yêu cầu kiến thức chuyên sâu về code: Làm sạch dữ liệu bằng Python thường đòi hỏi người dùng nắm vững các thư viện như Pandas, NumPy hay Sci-kit Learn. Không phải ai cũng có kỹ năng này, dẫn đến phụ thuộc vào các chuyên gia phân tích dữ liệu.
Phụ thuộc vào thao tác thủ công: Dù làm sạch dữ liệu bằng Python có hiệu quả, nhiều bước vẫn cần kiểm tra và điều chỉnh thủ công, đặc biệt với dữ liệu lớn hoặc liên tục cập nhật. Điều này làm chậm quy trình và tăng nguy cơ dữ liệu không đồng nhất.
Tắc nghẽn quy trình và rủi ro vận hành: Khi dữ liệu thay đổi liên tục, mỗi lần làm sạch lại cần chạy lại các quy trình, điều chỉnh code và kiểm tra kết quả, khiến tốc độ ra quyết định bị ảnh hưởng.
Tóm lại, phụ thuộc quá nhiều vào thao tác thủ công, code và kiến thức chuyên sâu là rào cản lớn khi làm sạch dữ liệu bằng Python. Doanh nghiệp cần cân nhắc xây dựng quy trình chuẩn, checklist, và kết hợp tự động hóa với giám sát thủ công hợp lý để đảm bảo dữ liệu sạch, nhất quán và giảm áp lực kỹ năng lập trình.
Điều mà các nhà quản trị thực sự quan tâm chính là: làm thế nào để làm sạch dữ liệu, chuẩn hoá và biến nó thành nền tảng tin cậy cho các quyết định chiến lược. Đây chính là khoảng trống mà phần mềm BCanvas xử lý và phân tích dữ liệu kinh doanh tích hợp AI được thiết kế để lấp đầy.
Điểm đột phá nằm ở tính năng Data Rubik. Không chỉ dừng lại ở khả năng xử lý bảng tính như Excel, Data Rubik được tích hợp AI để audit dữ liệu một cách tự động: phát hiện và loại bỏ trùng lặp, sửa lỗi định dạng, chuẩn hoá đơn vị đo lường, thậm chí cảnh báo bất thường trong dữ liệu giao dịch. Nhờ vậy, doanh nghiệp có thể xây dựng được một nguồn dữ liệu sạch, thống nhất và tin cậy.
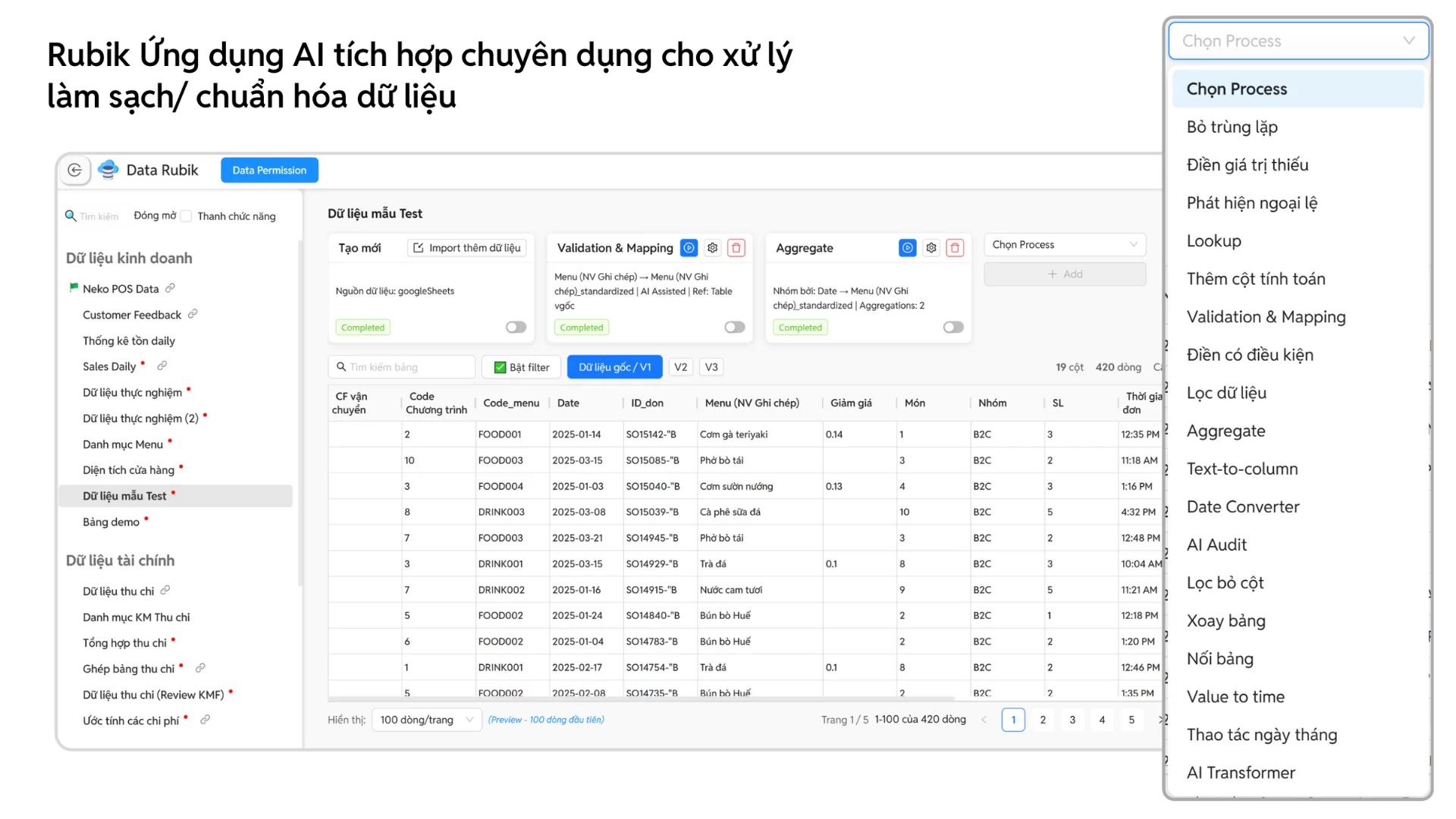
BCanvas còn có khả năng tạo mới hoặc ghi đè dữ liệu lên Google Sheet một cách tự động – tính năng hiện không khả dụng trong Power Query của Power BI, giúp đội ngũ kế toán hoặc nhân sự có thể dễ dàng cập nhật báo cáo mà không cần thao tác thủ công.
Một điểm mạnh khác là chế độ Auto Run: khi dữ liệu nguồn thay đổi (ví dụ file Excel hoặc Google Sheet được cập nhật), hệ thống sẽ tự động đồng bộ và làm mới dữ liệu trên dashboard. Nhờ đó, người dùng luôn theo dõi được số liệu mới nhất mà không cần can thiệp kỹ thuật.
Ngoài ra, khả năng kết nối và hợp nhất dữ liệu của BCanvas được tối ưu để đồng bộ tức thì với các phần mềm phổ biến tại Việt Nam như phần mềm kế toán, hệ thống POS, Excel, Google Sheets hay dữ liệu marketing từ mạng xã hội.
Dữ liệu sau khi được xử lý – làm sạch – chuẩn hoá (từ nhiều nguồn, loại bỏ trùng lặp, sai định dạng và tự động đối chiếu) tại Data Rubik, Công cụ Phân tích kinh doanh sẽ nhặt các chỉ số cụ thể từ KPI Map để chuyển dữ liệu thành hệ thống KPI động, phản ánh trung thực sức khoẻ của doanh nghiệp qua từng cấp độ phân tích: chiến lược – vận hành – bộ phận.
Khác với các công cụ quốc tế như Power BI hay Qlik, BCanvas được thiết kế đặc thù cho doanh nghiệp Việt, hỗ trợ tiếng Việt hoàn chỉnh và tương thích với môi trường dữ liệu trong nước. Ngoài ra, yếu tố chi phí cũng tạo nên sự khác biệt rõ rệt: so với các phần mềm quốc tế, BCanvas có chi phí giấy phép thấp hơn đáng kể, đặc biệt khi số lượng người dùng tăng lên, giúp doanh nghiệp dễ dàng triển khai rộng rãi.
Phần mềm BCanvas xử lý và phân tích dữ liệu kinh doanh tích hợp AI
TacaSoft,